

更新了使用空格来选择checkbox,避免一些报错。
必要第三方库有 requests 和 undetected_chromedriver
直接pip install x 安装,不会百度肯定有.
再者!!!,抢购的时候可能网站很卡响应时间太长(会报错?)所以建议把timesleep时间拉长,以免网页没加载完成点击事件会出错。
理论上Whcms的都可以买的,只要把两个URL,优惠码和最后付款界面的点击改一下,即可.前提不要验证码
建议放在国外小鸡上网速更快更好抢,linux,windows都可以。
使用方法直接保存代码为file.py,然后命令行python file.py 就可以了。
记得修改用户名,密码为自己的。
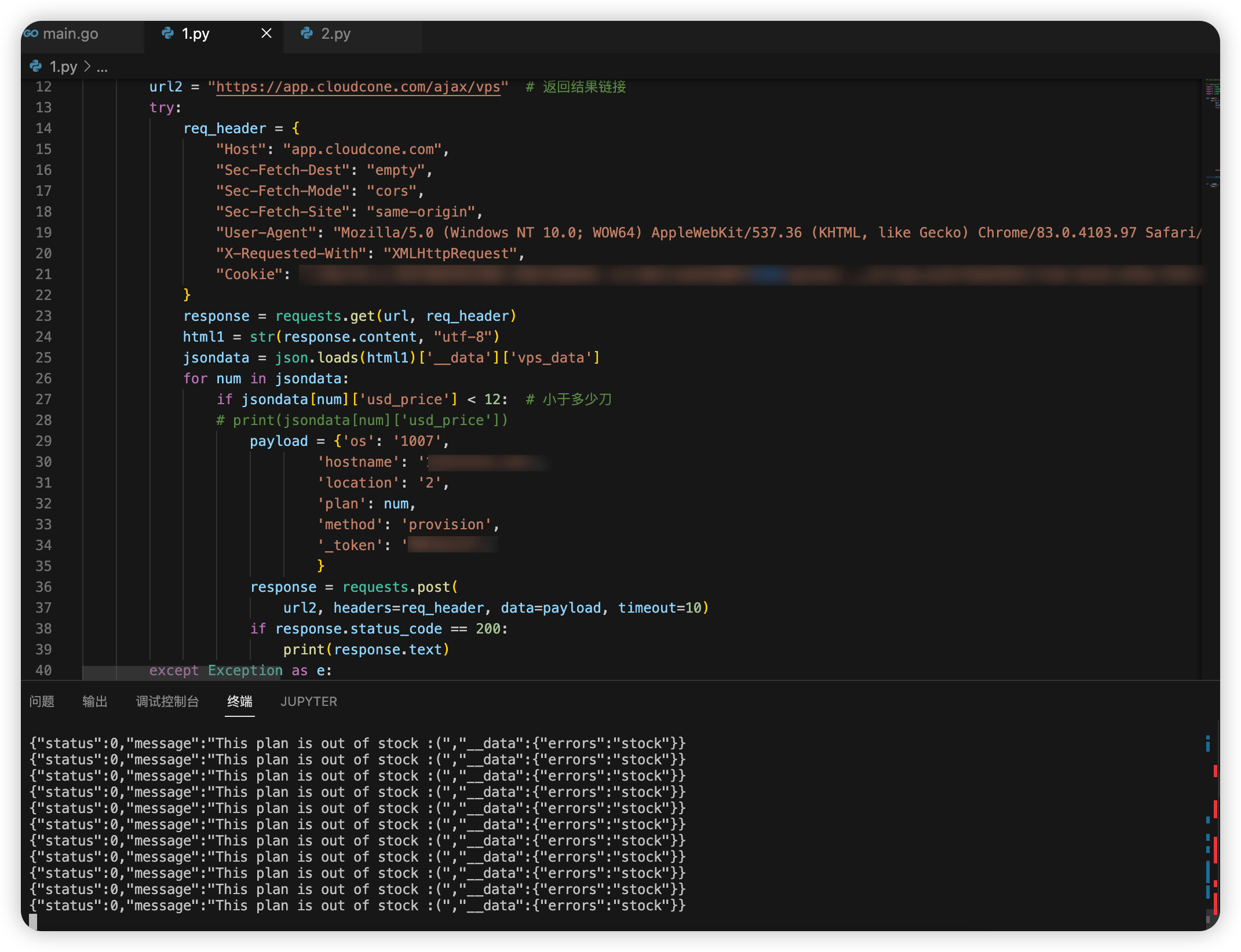
关于产品ID的获取
在产品 订购 上面右键检查元素,
<a href="/billing/store/10th-birthday-sale/1010-birthday-jp" class="btn btn-success btn-sm btn-order-now" id="product75-order-button">
<i class="fas fa-shopping-cart"></i>
Order Now
</a>id=”product75-order-button” 这个 product 后面的数字就是 pid
import undetected_chromedriver as uc
import requests
import time
import random
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
def buy_service():
# 这里是生成随机Hostname,你可以改为你的Hostname
hostname = str(random.randint(10000, 99999)) + '.baidu.com'
# 这里是生成随机密码,你可以改为你的密码
rootpw = ''.join(random.sample('zyxwvutsrqponmlkjihgfedcba!', 4)) + str(random.randint(100000, 999999))
print('Your root password:' + rootpw)
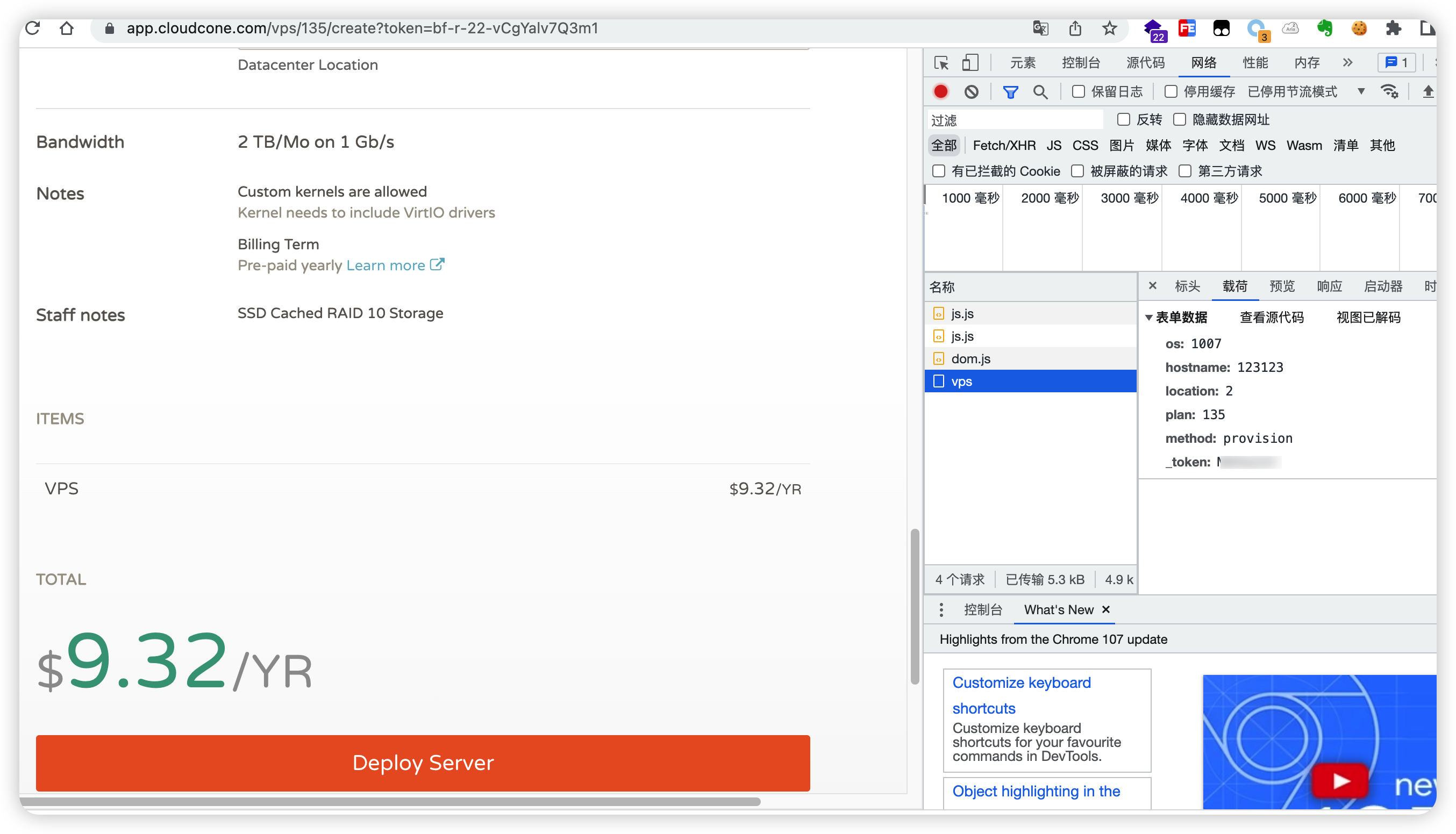
# 购买商品的链接 特价机的gid=60,演示中设置gid=25
url = 'https://www.greencloudvps.com/cart.php?a=add&pid=648'
uc_options = uc.ChromeOptions()
# 是否显示界面,linux下面这一行False改为True
uc_options.headless = False
# Then tried this option
driver = uc.Chrome(options=uc_options)
driver.set_window_size(700, 900) # 设置浏览器大小
# 打开网页
driver.get(url)
driver.find_element(by=By.XPATH, value='//input[@name="hostname"]').send_keys(hostname)
driver.find_element(by=By.XPATH, value='//input[@name="rootpw"]').send_keys(rootpw)
driver.find_element(by=By.XPATH, value='//input[@name="ns1prefix"]').send_keys('www')
driver.find_element(by=By.XPATH, value='//input[@name="ns2prefix"]').send_keys('www')
driver.find_element(by=By.XPATH, value='//*[@id="btnCompleteProductConfig"]').click()
time.sleep(2)
try_time = 1
# 有优惠码的时候使用
# for try_time in range(1, 7):
# try:
# time.sleep(0.24)
# driver.find_element(by=By.XPATH, value='//input[@name="promocode"]').send_keys('')
# except Exception:
# try_time = try_time + 1
# pass
# if try_time == 6:
# print("得你手动了骚年!")
# break
# else:
# break
# driver.find_element(by=By.XPATH, value='/html/body/section[2]/div/div/div/div[1]/div/div/div[3]/div[2]/div[1]/div/div/div[1]/form/button').click()
# time.sleep(0.7)
driver.find_element(by=By.XPATH, value='//*[@id = "checkout"]').click()
time.sleep(2)
driver.find_element(by=By.XPATH, value='//button[@id="btnAlreadyRegistered"]').click()
# 购买者邮箱
time.sleep(2)
driver.find_element(by=By.XPATH, value='//input[@name="loginemail"]').send_keys("username@qq.com")
# 账号密码
driver.find_element(by=By.XPATH, value='//input[@name="loginpassword"]').send_keys("passwd")
# 最后这一行是付款界面的"点击结算".如果你想要测试脚本是否正常运行,可以先把这一句去掉,以免购买了给你发账单(虽然可以不付款)+
driver.find_element(by=By.XPATH, value='//input[@value="payssionalipaycn"]').send_keys(Keys.SPACE)
driver.find_element(by=By.XPATH, value='//input[@id="accepttos"]').send_keys(Keys.SPACE)
time.sleep(2)
driver.find_element(by=By.XPATH, value='//button[@id="btnCompleteOrder"]').click()
print("抢购成功!")
if __name__ == '__main__':
order = False
header = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
# 逻辑判断
while not order:
# 检测商品上货的链接 特价机的gid=60,演示中设置gid=25
response = requests.get(url='https://www.greencloudvps.com/cart.php?a=add&pid=648', headers=header)
if 'Out of Stock' in str(response.content):
print('Mei Huo')
print('时间:' + time.strftime('%H:%M:%S'))
print("*" * 30)
time.sleep(3)
else:
order = True
if order:
buy_service()








插图")
插图1")
插图2")
插图3")
插图4")
插图5")
插图6")
插图7")
插图8")
插图9")