
无需更改任何代码,文件上传网站直接调用就可以。
调用方法:域名/?url= 示例:http://www.baidu.com/?url=
支持二级目录或多级目录


简易高效的代理池,提供如下功能:
代理池原理解析可见「如何搭建一个高效的代理池」,建议使用之前阅读。
首先当然是克隆代码并进入 ProxyPool 文件夹:
git clone https://github.com/Python3WebSpider/ProxyPool.git
cd ProxyPool
然后选用下面 Docker 和常规方式任意一个执行即可。
可以通过两种方式来运行代理池,一种方式是使用 Docker(推荐),另一种方式是常规方式运行,要求如下:
如果使用 Docker,则需要安装如下环境:
安装方法自行搜索即可。
常规方式要求有 Python 环境、Redis 环境,具体要求如下:
如果安装好了 Docker 和 Docker-Compose,只需要一条命令即可运行。docker-compose up
运行结果类似如下:
redis | 1:M 19 Feb 2020 17:09:43.940 * DB loaded from disk: 0.000 seconds
redis | 1:M 19 Feb 2020 17:09:43.940 * Ready to accept connections
proxypool | 2020-02-19 17:09:44,200 CRIT Supervisor is running as root. Privileges were not dropped because no user is specified in the config file. If you intend to run as root, you can set user=root in the config file to avoid this message.
proxypool | 2020-02-19 17:09:44,203 INFO supervisord started with pid 1
proxypool | 2020-02-19 17:09:45,209 INFO spawned: 'getter' with pid 10
proxypool | 2020-02-19 17:09:45,212 INFO spawned: 'server' with pid 11
proxypool | 2020-02-19 17:09:45,216 INFO spawned: 'tester' with pid 12
proxypool | 2020-02-19 17:09:46,596 INFO success: getter entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
proxypool | 2020-02-19 17:09:46,596 INFO success: server entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
proxypool | 2020-02-19 17:09:46,596 INFO success: tester entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
可以看到 Redis、Getter、Server、Tester 都已经启动成功。
这时候访问 http://localhost:5555/random 即可获取一个随机可用代理。
当然你也可以选择自己 Build,直接运行如下命令即可:
docker-compose -f build.yaml up
如果下载速度特别慢,可以自行修改 Dockerfile,修改:- RUN pip install -r requirements.txt + RUN pip install -r requirements.txt -i https://pypi.douban.com/simple
如果不使用 Docker 运行,配置好 Python、Redis 环境之后也可运行,步骤如下。
本地安装 Redis、Docker 启动 Redis、远程 Redis 都是可以的,只要能正常连接使用即可。
首先可以需要一下环境变量,代理池会通过环境变量读取这些值。
设置 Redis 的环境变量有两种方式,一种是分别设置 host、port、password,另一种是设置连接字符串,设置方法分别如下:
设置 host、port、password,如果 password 为空可以设置为空字符串,示例如下:export PROXYPOOL_REDIS_HOST=’localhost’ export PROXYPOOL_REDIS_PORT=6379 export PROXYPOOL_REDIS_PASSWORD=” export PROXYPOOL_REDIS_DB=0
或者只设置连接字符串:export PROXYPOOL_REDIS_CONNECTION_STRING=’redis://localhost’
这里连接字符串的格式需要符合 redis://[:password@]host[:port][/database] 的格式, 中括号参数可以省略,port 默认是 6379,database 默认是 0,密码默认为空。
以上两种设置任选其一即可。
这里强烈推荐使用 Conda 或 virtualenv 创建虚拟环境,Python 版本不低于 3.6。
然后 pip 安装依赖即可:pip3 install -r requirements.txt
两种方式运行代理池,一种是 Tester、Getter、Server 全部运行,另一种是按需分别运行。
一般来说可以选择全部运行,命令如下:python3 run.py
运行之后会启动 Tester、Getter、Server,这时访问 http://localhost:5555/random 即可获取一个随机可用代理。
或者如果你弄清楚了代理池的架构,可以按需分别运行,命令如下:python3 run.py –processor getter python3 run.py –processor tester python3 run.py –processor server
这里 processor 可以指定运行 Tester、Getter 还是 Server。
成功运行之后可以通过 http://localhost:5555/random 获取一个随机可用代理。
可以用程序对接实现,下面的示例展示了获取代理并爬取网页的过程:import requests proxypool_url = ‘http://127.0.0.1:5555/random’ target_url = ‘http://httpbin.org/get’ def get_random_proxy(): “”” get random proxy from proxypool :return: proxy “”” return requests.get(proxypool_url).text.strip() def crawl(url, proxy): “”” use proxy to crawl page :param url: page url :param proxy: proxy, such as 8.8.8.8:8888 :return: html “”” proxies = {‘http’: ‘http://’ + proxy} return requests.get(url, proxies=proxies).text def main(): “”” main method, entry point :return: none “”” proxy = get_random_proxy() print(‘get random proxy’, proxy) html = crawl(target_url, proxy) print(html) if __name__ == ‘__main__’: main()
运行结果如下:
get random proxy 116.196.115.209:8080
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5e4d7140-662d9053c0a2e513c7278364"
},
"origin": "116.196.115.209",
"url": "https://httpbin.org/get"
}
可以看到成功获取了代理,并请求 httpbin.org 验证了代理的可用性。
代理池可以通过设置环境变量来配置一些参数。
gevent, 可选:tornado,meinheld(分别需要安装 tornado 或 meinheld 模块)以上内容均可使用环境变量配置,即在运行前设置对应环境变量值即可,如更改测试地址和 Redis 键名:export TEST_URL=http://weibo.cn export REDIS_KEY=proxies:weibo
即可构建一个专属于微博的代理池,有效的代理都是可以爬取微博的。
如果使用 Docker-Compose 启动代理池,则需要在 docker-compose.yml 文件里面指定环境变量,如:version: “3” services: redis: image: redis:alpine container_name: redis command: redis-server ports: – “6379:6379” restart: always proxypool: build: . image: “germey/proxypool” container_name: proxypool ports: – “5555:5555” restart: always environment: REDIS_HOST: redis TEST_URL: http://weibo.cn REDIS_KEY: proxies:weibo
代理的爬虫均放置在 proxypool/crawlers 文件夹下,目前对接了有限几个代理的爬虫。
若扩展一个爬虫,只需要在 crawlers 文件夹下新建一个 Python 文件声明一个 Class 即可。
写法规范如下:from pyquery import PyQuery as pq from proxypool.schemas.proxy import Proxy from proxypool.crawlers.base import BaseCrawler BASE_URL = ‘http://www.664ip.cn/{page}.html’ MAX_PAGE = 5 class Daili66Crawler(BaseCrawler): “”” daili66 crawler, http://www.66ip.cn/1.html “”” urls = [BASE_URL.format(page=page) for page in range(1, MAX_PAGE + 1)] def parse(self, html): “”” parse html file to get proxies :return: “”” doc = pq(html) trs = doc(‘.containerbox table tr:gt(0)’).items() for tr in trs: host = tr.find(‘td:nth-child(1)’).text() port = int(tr.find(‘td:nth-child(2)’).text()) yield Proxy(host=host, port=port)
在这里只需要定义一个 Crawler 继承 BaseCrawler 即可,然后定义好 urls 变量和 parse 方法即可。
网页的爬取不需要实现,BaseCrawler 已经有了默认实现,如需更改爬取方式,重写 crawl 方法即可。

本工具是基于兴趣及代码研究所创作,严禁用于商业用途及任何不法用途。本代码完全免费,严禁任何人将本代码用于出售及其它类似商业行为。
94采集器是一款非常受欢迎的可用于linux或者windows双平台的采集系统。相对于关关只能在Windows上运行来说,太香了。
但是94采集器也有一些缺点,比较代码全是中文,中文函数,中文变量,中文类,非常难以理解。另外就是采集效率上,94是比较容易内存溢出的,导致动辄卡死。另外在对比的效率以及加书的效率上来说,都有不小的问题。
但94的优点同样不少,前文说的跨平台是其一大优势。94兼容的系统比较多也是一大优势;另外,因为python本身库比较多,实现类似cloudflare 5秒盾这样的突破就变得轻而易举。
鉴于对这么优秀的系统的兴趣,对其进行了一系列的修改优化,主要从以下几个方面
本系统免费分享给对爬虫技术有兴趣的朋友,为防止泛滥,所以只限Vip用户组下载。
请大家自行研究,不要分发。
再次申明,此代码仅供研究技术使用,严禁用于不法用途,违者后果自负。

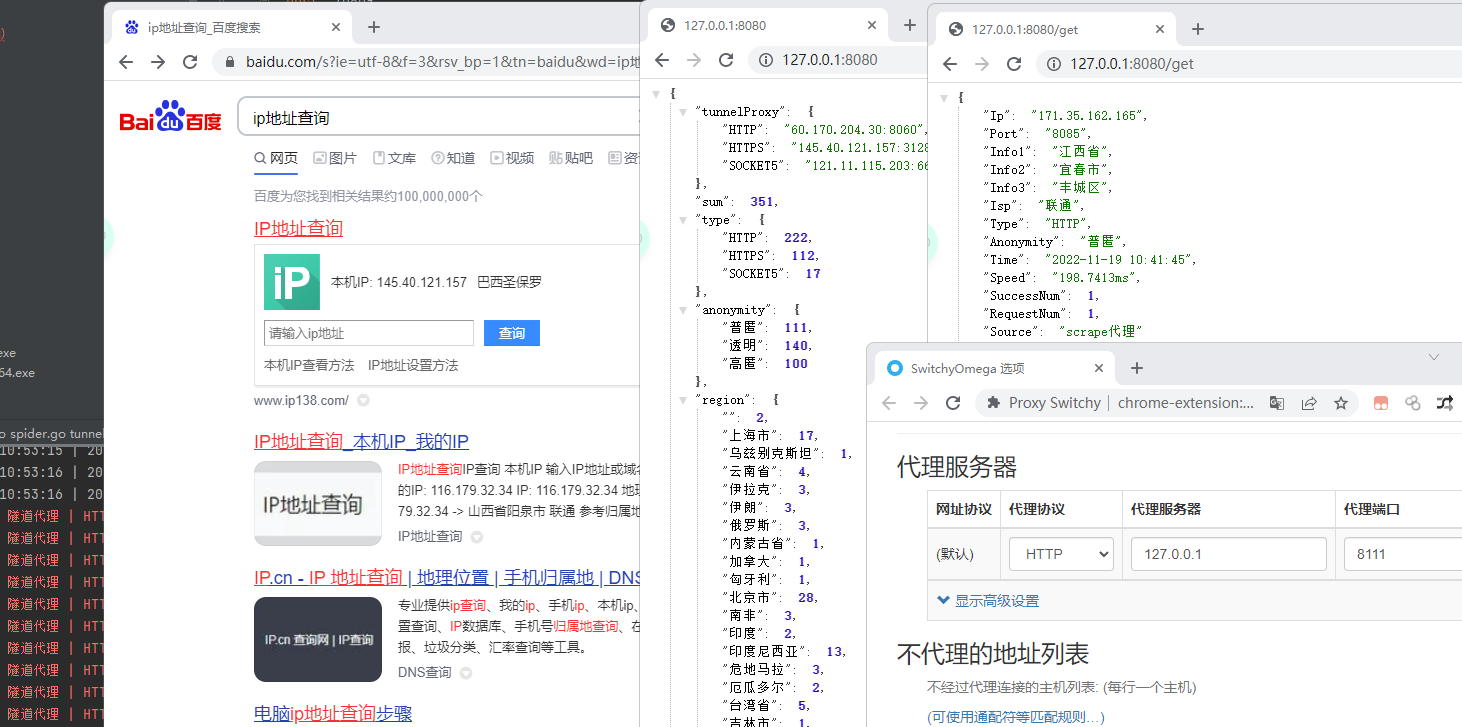
爬虫爬多了总会被封IP,这个时候你需要去找代理。现在的代理方式主要有代理ip池,每次请求几个ip都是自定义的,这种一年普遍的价格是600¥;还有一种叫隧道代理,就是你访问的是固定的域名:端口的形式,然后服务端会使用不固定的代理ip访问,这种和代理ip池其实没有本质区别,只是一种是自己直接使用代理ip爬取,一种是使用远程服务器爬取并返回内容。这种隧道代理现在普遍好像要3000¥一年,真的是贵的不行了。
当然,前面说的都是要钱的,今天给大家一个免费的工具,可以自己搭建动态ip代理池或者隧道代理,相信学会怎么使用后,你也可以去卖代理ip池或者隧道代理了。
本站提供的下载是在原有的基础上增加了一些代理源,可用性相对更高一些。
protocol:"socks5" AND "Accepted Auth Method: 0x0" AND "connection: close" AND country: "China"
"HTTP/1.1 403 Forbidden Server: nginx/1.12.1" && port="9091"
port="3128" && title="ERROR: The requested URL could not be retrieved"
"X-Cache: 'MISS from VideoCacheBox/CE8265A63696DECD7F0D17858B1BDADC37771805'" && "X-Squid-Error: ERR_ACCESS_DENIED 0"
header.server="nginx/2.2.200603d"&&web.title="502 Bad Gateway" && ip.port="8085"
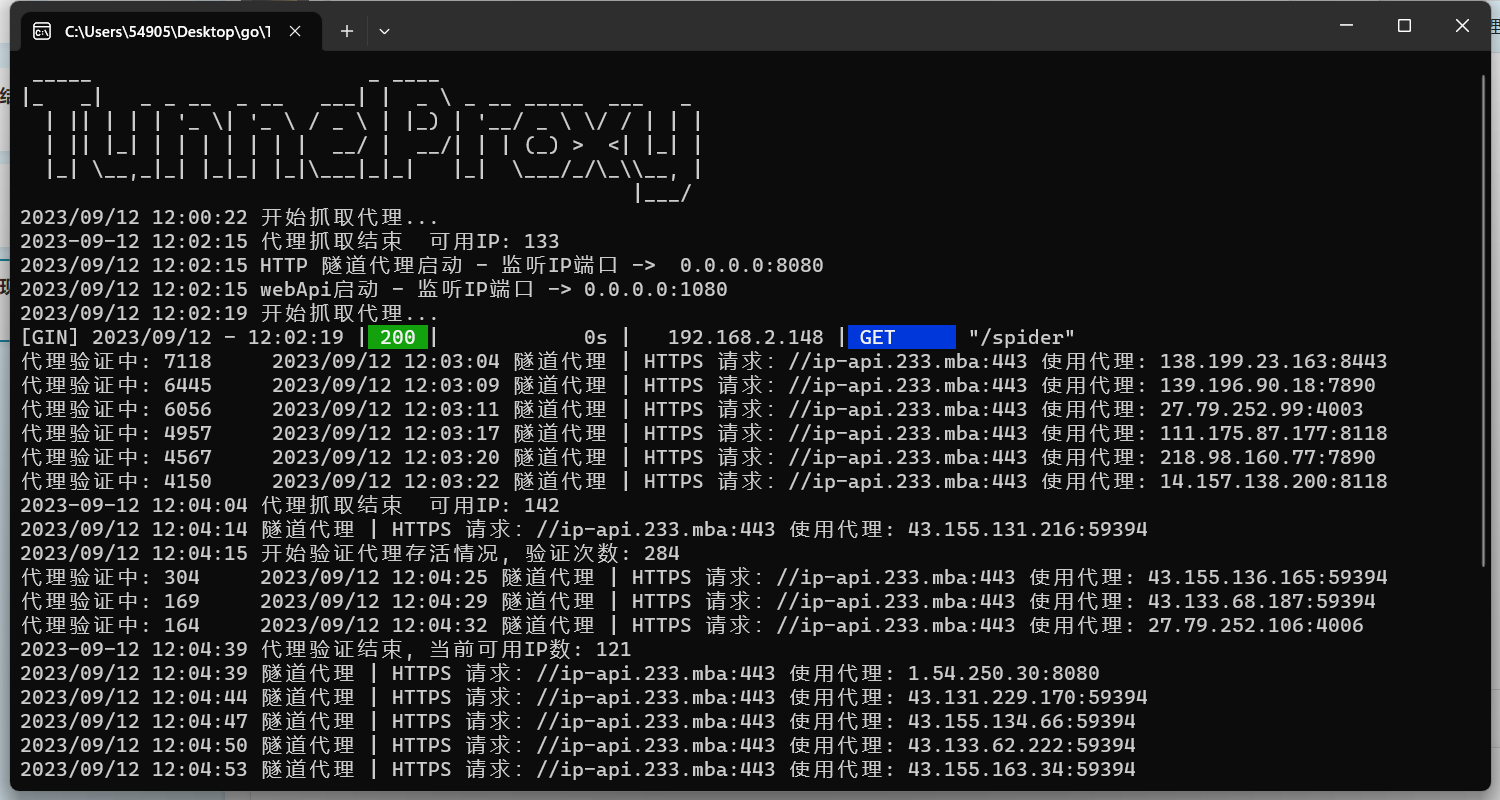
git clone https://github.com/FynnFbc/TunnelProxyPool.git
set CGO_ENABLED=0
set GOOS=windows
set GOARCH=amd64
go build -ldflags "-s -w" -o ../ProxyPool-win-64.exe
set CGO_ENABLED=0
set GOOS=windows
set GOARCH=386
go build -ldflags "-s -w" -o ../ProxyPool-win-86.exe
set CGO_ENABLED=0
set GOOS=linux
set GOARCH=amd64
go build -ldflags "-s -w" -o ../ProxyPool-linux-64
set CGO_ENABLED=0
set GOOS=linux
set GOARCH=arm64
go build -ldflags "-s -w" -o ../ProxyPool-linux-arm64
set CGO_ENABLED=0
set GOOS=linux
set GOARCH=386
go build -ldflags "-s -w" -o ../ProxyPool-linux-86
set CGO_ENABLED=0
set GOOS=darwin
set GOARCH=amd64
go build -ldflags "-s -w" -o ../ProxyPool-macos-64
set CGO_ENABLED=0
set GOOS=darwin
set GOARCH=arm64
go build -ldflags "-s -w" -o ../ProxyPool-macos-arm64
.\ProxyPool.exe
proxy: host: 127.0.0.1 port: 10809
http://127.0.0.1:8080/
http://127.0.0.1:8080/get?type=HTTP&count=10&anonymity=all
可选参数:
type 代理类型
anonymity 匿名度
country 国家
source 代理源
count 代理数量
获取所有:all
http://127.0.0.1:8080/delete?ip=127.0.0.1&port=8888
必须传参:
ip 代理ip
port 代理端口
http://127.0.0.1:8080/verify
http://127.0.0.1:8080/spider
type ProxyIp struct { Ip string //IP地址 Port string //代理端口 Country string //代理国家 Province string //代理省份 City string //代理城市 Isp string //IP提供商 Type string //代理类型 Anonymity string //代理匿名度, 透明:显示真实IP, 普匿:显示假的IP, 高匿:无代理IP特征 Time string //代理验证 Speed string //代理响应速度 SuccessNum int //验证请求成功的次数 RequestNum int //验证请求的次数 Source string //代理源 }
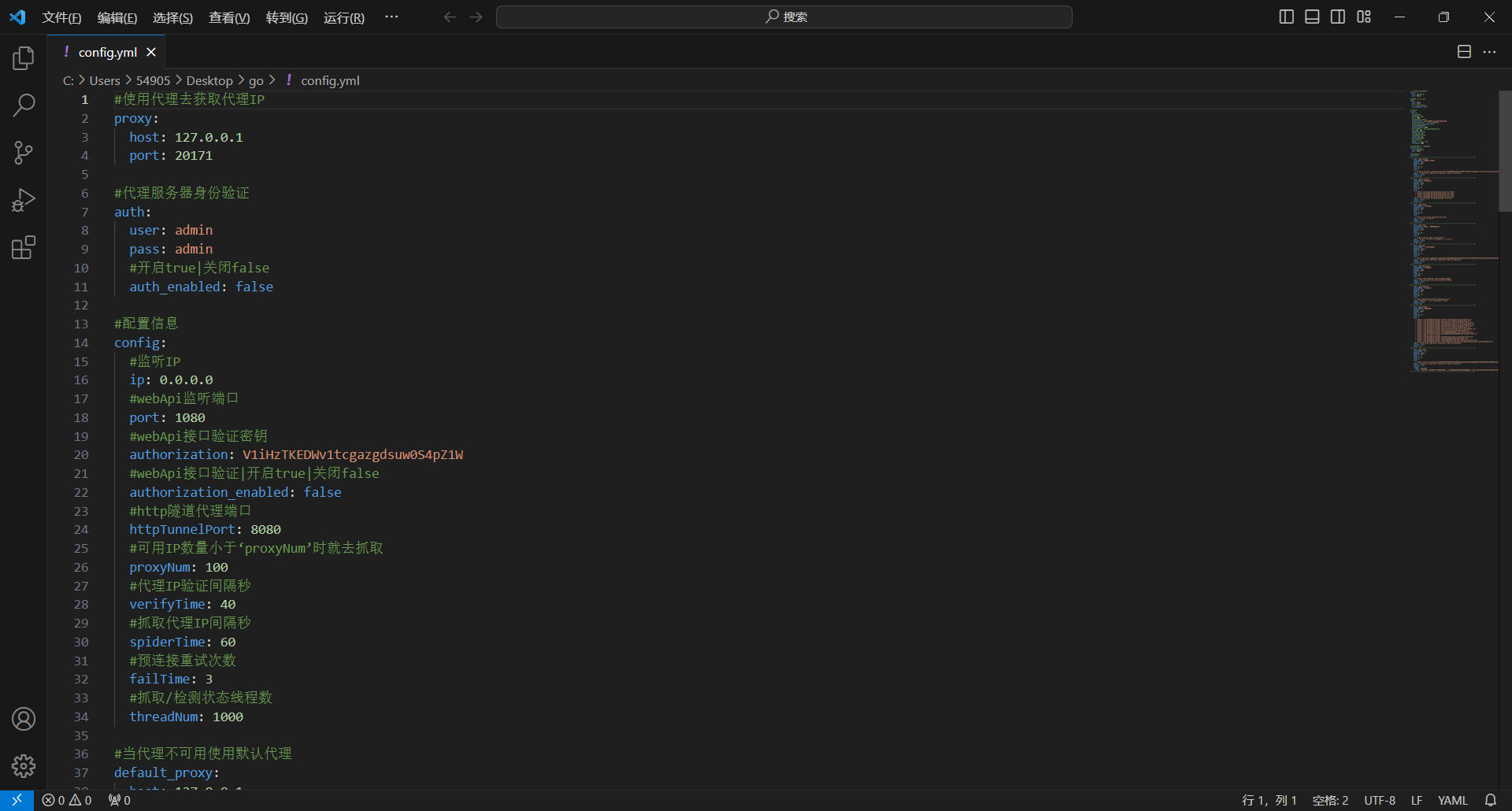
# 使用代理去获取代理IP proxy: host: 127.0.0.1 port: 10809 # 代理身份验证 auth: # 用户名 user: abcde # 密码 pass: qwert # 配置信息 config: #监听IP ip: 0.0.0.0 #web监听端口 port: 8080 #http隧道代理端口 httpTunnelPort: 8111 #socket隧道代理端口 socketTunnelPort: 8112 #隧道代理更换时间秒 tunnelTime: 60 #可用IP数量小于‘proxyNum’时就去抓取 proxyNum: 50 #代理IP验证间隔秒 verifyTime: 1800 #抓取/检测状态线程数 threadNum: 200
2022/11/22
修复 ip归属地接口更换
优化 验证代理
2022/11/19
新增 socket5代理
新增 文件导入代理
新增 显示验证进度
新增 验证webApi
修改 扩展导入格式
优化 代理验证方式
优化 匿名度改为自动识别
修复 若干bug
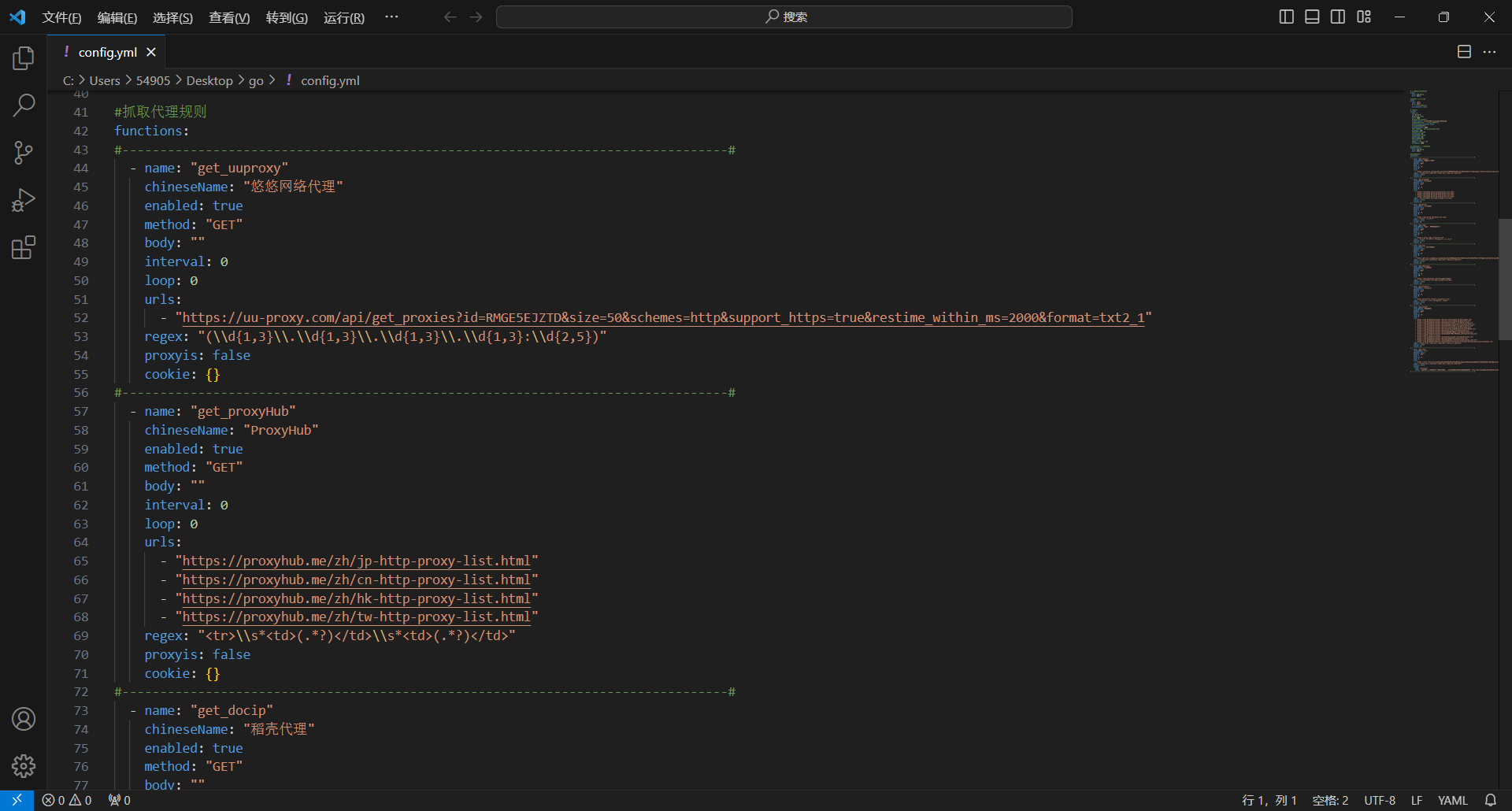
__init__.py新建文件 ,内容如下
import os
from flask import Flask
from config import Config
from datetime import timedelta
from app.logs import log
from app.helper import filehelper, taskhelper
from app.helper.schehelper import scheduler
def app():
try:
path = os.getcwd()
tpath = '{0}//templates'.format(path.replace("\\", "//"))
spath = '{0}//static'.format(path.replace("\\", "//"))
appflask = Flask(__name__) # , template_folder=tpath, static_folder=spath
appflask.config.from_object(Config())
# 自动重载模板文件
appflask.jinja_env.auto_reload = True
appflask.config['TEMPLATES_AUTO_RELOAD'] = True
# 设置静态文件缓存过期时间
appflask.config['SEND_FILE_MAX_AGE_DEFAULT'] = timedelta(seconds=1)
appflask.config['JSON_AS_ASCII'] = False # 这个配置可以确保http请求返回的json数据中正常显示中文
读取基础配置()
#scheduler.init_app(appflask)
scheduler.start()
return appflask
except Exception as e:
msg = 'app-{0},文件地址:{1},错误行号:{2}'.format(e, e.__traceback__.tb_frame.f_globals["__file__"],
e.__traceback__.tb_lineno)
log.错误日志(msg)
def 读取基础配置():
try:
系统设置 = filehelper.读INI("系统设置.ini", "系统设置", "系统设置")
Config.系统设置 = eval(系统设置)
大类设置 = filehelper.读INI("大类设置.ini", "大类设置", "大类设置")
Config.一级分类 = 大类设置.strip('\n').split('\n')
小类设置 = filehelper.读INI("小类设置.ini", "小类设置", "小类设置")
Config.二级分类 = 小类设置.strip('\n').split('\n')
频道设置 = filehelper.读INI("频道设置.ini", "频道设置", "频道设置")
Config.频道 = 频道设置.strip('\n').split('\n')
连载设置 = filehelper.读INI("连载设置.ini", "连载设置", "连载设置")
Config.连载 = 连载设置.strip('\n').split('\n')
标识设置 = filehelper.读INI("标识设置.ini", "标识设置", "标识设置")
Config.标识 = 标识设置.strip('\n').split('\n')
自定内容 = filehelper.读INI("自定内容.ini", "自定内容", "自定内容")
Config.自定内容 = 自定内容
UA设置 = filehelper.读INI("UA设置.ini", "UA设置", "UA设置")
Config.UA = UA设置.split('\n')
代理设置 = filehelper.读INI("代理设置.ini", "代理设置", "代理设置")
Config.代理 = 代理设置.strip('\n').split('\n')
邮件设置 = filehelper.读INI("邮件设置.ini", "邮件设置", "邮件设置")
Config.邮件 = eval(邮件设置)
规则列表 = filehelper.读取任务列表()
for item in 规则列表:
if item.startswith('任务'):
任务ID = item.replace('任务', '').replace('.ini', '')
任务字符串 = filehelper.读INI('任务{0}.ini'.format(任务ID), 任务ID, 'taskinfo')
任务信息 = eval(任务字符串)
taskhelper.添加任务(任务信息)
except Exception as e:
msg = '读取基础配置-{0},文件地址:{1},错误行号:{2}'.format(e, e.__traceback__.tb_frame.f_globals["__file__"],
e.__traceback__.tb_lineno)
log.错误日志(msg)
新建 task.py文件,内容如下
# -*- coding: UTF-8 -*-
import json
import base64
import datetime
from config import Config
from app.helper import filehelper, commonhelper, taskhelper
from flask import request, render_template
def 查询任务列表():
try:
规则列表 = filehelper.读取任务列表()
返回值 = []
for item in 规则列表:
if item.startswith('任务'):
任务ID = item.replace('任务', '').replace('.ini', '')
规则ID = filehelper.读INI('任务{0}.ini'.format(任务ID), 任务ID, 'taskname')
任务名称 = filehelper.读INI('任务{0}.ini'.format(任务ID), 任务ID, 'taskname')
任务类型 = filehelper.读INI('任务{0}.ini'.format(任务ID), 任务ID, 'taskType')
任务状态 = filehelper.读INI('任务{0}.ini'.format(任务ID), 任务ID, 'taskstatus')
任务时间间隔 = filehelper.读INI('任务{0}.ini'.format(任务ID), 任务ID, 'tasktime')
采集内容 = commonhelper.获取当前采集信息(任务ID)
最后运行时间 = filehelper.读INI('任务{0}.ini'.format(任务ID), 任务ID, 'gxsj')
返回值.append({
"任务ID": 任务ID,
"规则ID": 规则ID,
"任务名称": 任务名称,
"任务类型": 任务类型,
"任务状态": 任务状态,
"任务时间间隔": 任务时间间隔,
"采集内容": 采集内容,
"最后运行时间": 最后运行时间
})
return '{"code":0,"msg":"", "count":' + str(len(返回值)) + ', "data": ' + json.dumps(返回值) + '}'
except Exception as e:
return '{"code":0,"msg":"' + e + '","count":0,"data":[]}'
def 添加任务():
try:
taskid = str(request.form['taskid'])
ruleid = str(request.form['ruleid'])
taskname = str(request.form['taskname'])
tasktime = str(request.form['tasktime'])
taksmode = str(request.form['taksmode'])
taskType = str(request.form['taskType'])
bookid = str(request.form['bookid'])
startid = str(request.form['startid'])
endid = str(request.form['endid'])
startpage = str(request.form['startpage'])
endpage = str(request.form['endpage'])
pagelist = str(request.form['pagelist'])
isimg = str(request.form['isimg'])
isinfo = str(request.form['isinfo'])
ismark = str(request.form['ismark'])
sizerestoration = str(request.form['sizerestoration'])
colletime = str(request.form['colletime'])
retrynum = str(request.form['retrynum'])
retrytime = str(request.form['retrytime'])
useragent = str(request.form['useragent'])
contrastmethod = str(request.form['contrastmethod'])
an = str(request.form['an'])
cn = str(request.form['cn'])
yj = str(request.form['yj'])
dl = str(request.form['dl'])
dlinfo = str(request.form['dlinfo'])
cookies = str(request.form['cookies'])
bcjbt = str(request.form['bcjbt'])
minichapter = str(request.form['minichapter'])
bookurl = str(request.form['bookurl'])
booklisturl = str(request.form['booklisturl'])
maxchapter = str(request.form['maxchapter'])
iscf5 = str(request.form['iscf5'])
是否添加 = False
if (taskid == None) | (taskid == 'None') | (taskid == ''):
taskid = datetime.datetime.now().strftime("%Y%m%d%H%m%f")
是否添加 = True
任务信息 = {
"taskid": taskid,
"ruleid": ruleid,
"taskname": taskname,
"tasktime": tasktime,
"taksmode": taksmode,
"taskType": taskType,
"bookid": bookid,
"bookurl": bookurl,
"startid": startid,
"endid": endid,
"booklisturl": booklisturl,
"startpage": startpage,
"endpage": endpage,
"pagelist": pagelist,
"isimg": isimg,
"isinfo": isinfo,
"ismark": ismark,
"sizerestoration": sizerestoration,
"colletime": colletime,
"retrynum": retrynum,
"retrytime": retrytime,
"useragent": useragent,
"contrastmethod": contrastmethod,
"an": an,
"cn": cn,
"yj": yj,
"dl": dl,
"dlinfo": dlinfo,
"cookies": cookies,
"bcjbt": bcjbt,
"minichapter": minichapter,
"maxchapter": maxchapter,
"iscf5":iscf5
}
if filehelper.写入任务INI(taskid, taskid, 任务信息):
if 是否添加:
taskhelper.添加任务(任务信息)
else:
taskhelper.修改任务(任务信息)
taskhelper.获取任务信息(taskid)
return '保存成功!'
else:
return '保存失败!'
except Exception as e:
msg = '{0},文件地址:{1},错误行号:{2}'.format(e, e.__traceback__.tb_frame.f_globals["__file__"],
e.__traceback__.tb_lineno)
return msg
def 查询任务信息():
try:
类型 = str(request.args.get('type'))
任务信息 = {}
规则信息 = []
if 类型 == 'add':
pass
elif 类型 == 'up':
任务ID = str(request.args.get('taskid'))
任务字符串 = filehelper.读INI('任务{0}.ini'.format(任务ID), 任务ID, 'taskinfo')
任务信息 = eval(任务字符串)
规则列表 = filehelper.读取规则列表()
for item in 规则列表:
规则ID = filehelper.读INI('规则.ini', item, 'ruleid')
规则名称 = filehelper.读INI('规则.ini', item, 'rulename')
规则信息.append({"v": 规则ID, "t": 规则名称})
return render_template("task.html", info=任务信息, 规则=规则信息, UserAgent=Config.UA)
except Exception as e:
msg = '{0},文件地址:{1},错误行号:{2}'.format(e, e.__traceback__.tb_frame.f_globals["__file__"],
e.__traceback__.tb_lineno)
return render_template("msg.html", info=msg)
def 启动任务():
try:
任务ID = str(request.args.get('taskid'))
if filehelper.修改INI('任务{0}.ini'.format(任务ID), 任务ID, "taskstatus", "开启"):
return '启动成功!'
else:
return '启动失败!'
except Exception as e:
msg = '{0},文件地址:{1},错误行号:{2}'.format(e, e.__traceback__.tb_frame.f_globals["__file__"],
e.__traceback__.tb_lineno)
return msg
def 暂停任务():
try:
任务ID = str(request.args.get('taskid'))
if filehelper.修改INI('任务{0}.ini'.format(任务ID), 任务ID, "taskstatus", "暂停"):
return '暂停成功!'
else:
return '暂停失败!'
except Exception as e:
msg = '{0},文件地址:{1},错误行号:{2}'.format(e, e.__traceback__.tb_frame.f_globals["__file__"],
e.__traceback__.tb_lineno)
return msg
def 删除任务信息():
try:
任务ID = str(request.args.get('taskid'))
if filehelper.删除任务INI(任务ID):
taskhelper.删除任务(任务ID)
return '删除成功!'
else:
return '删除失败!'
except Exception as e:
msg = '{0},文件地址:{1},错误行号:{2}'.format(e, e.__traceback__.tb_frame.f_globals["__file__"],
e.__traceback__.tb_lineno)
return msg
def 批量删除任务信息():
try:
任务ID = str(request.form['taskId'])
任务列表 = 任务ID.split('|')
成功数量 = 0
失败数量 = 0
for item in 任务列表:
if filehelper.删除任务INI(任务ID):
taskhelper.删除任务(任务ID)
成功数量 = 成功数量 + 1
else:
失败数量 = 失败数量 + 1
return '成功删除{0}条,失败{1}条!'.format(成功数量, 失败数量)
except Exception as e:
msg = '{0},文件地址:{1},错误行号:{2}'.format(e, e.__traceback__.tb_frame.f_globals["__file__"],
e.__traceback__.tb_lineno)
return msg
task.py文件放入app/view文件夹
原来对应的pyc文件可以删除。
替换完成后重启应用服务器即可。

我们想确定一个网站的真实IP地址,通常现在网站都会使用https协议,用到SSL证书是必不可少的,绝大多数企业证书都是通配符证书,因此我们可以把证书的序列号拿下来然后搜索这个证书用在了哪些业务里,然后如果部分业务中没有使用CDN或者没有覆盖到CDN,源IP地址就显示出来了!
这里以知乎网站为例,我们先访问网站,然后按F12打开开发者工具,点击Security
![图片[1]-使用Fofa确定网站真实IP地址的小技巧-FancyPig's blog](https://www.wucuoym.com/wp-content/uploads/2023/07/20210929071657929-1024x469-1.png)
点击View certificate,查看证书详情
![图片[2]-使用Fofa确定网站真实IP地址的小技巧-FancyPig's blog](https://www.wucuoym.com/wp-content/uploads/2023/07/20210929071636660-1024x526-1.png)
这里有详细信息,其中我们可以看到序列号
![图片[3]-使用Fofa确定网站真实IP地址的小技巧-FancyPig's blog](https://www.wucuoym.com/wp-content/uploads/2023/07/20210929071729969.png)
0aebda9950b9ae3faaa3a00e68fc5565
然后,我们使用在线转换工具,将16进制的序列号转换为10进制
14516903431790578896883864801849922917
![图片[4]-使用Fofa确定网站真实IP地址的小技巧-FancyPig's blog](https://www.wucuoym.com/wp-content/uploads/2023/07/20210929071827250.png)
这时候Fofa的作用就来了,我们可以通过下面的语句来进行调查
cert="14516903431790578896883864801849922917"
![图片[5]-使用Fofa确定网站真实IP地址的小技巧-FancyPig's blog](https://www.wucuoym.com/wp-content/uploads/2023/07/20210929071920460-1024x495-1.png)

解压后看到的文件有:

其中discusX3.0.wpm 是发布模块,dz测试接口.ljobx 是用于测试的规则,以后不要问规则该怎么写了,就按照这个格式写。
1,上传接口
根据自己的网站编码选择GBk或者utf8文件下下面的接口文件,jiekou.php,这个接口有个密码,默认是123456,如果想要修改,就打开这个jiekou.php,修改:

就是上图这个,把默认的“123456”修改成你想要的,修改好了一定要保存,看不懂那就不要修改了。
然后把这个文件上传到DZ网站的根目录,不知道什么是根目录的自己百度,不要问上传到那里,自己的网站
别人怎么知道你的根目录是什么,不知道就自己去查。
然后我们在浏览器里试试能不能访问,访问地址是http://网站域名/jiekou.php?pw=密码, 这个密码就是上面说的接口密码:
如果能出现论坛的模块就证明接口是对的了。
2,导入发布模块
点击发布按钮:
成功导入后会有提示的。
发布模块设置:
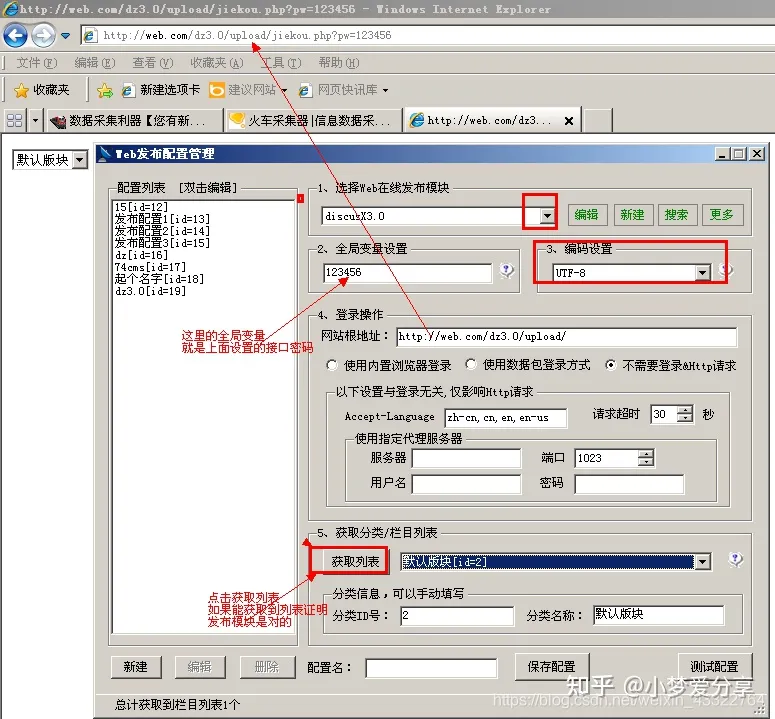
第一步,选择我们刚才导入的dz发布模块。
第二步:全局变量就是上面说的接口文件密码
第三步:选择对应的编码
第四步:网站根目录就填写上面我们访问接口的时候去掉后面的接口文件名称,剩余后的地址。然后选择“不需要登录&Http请求”
第五步:点击获取列表,如果能显示论坛版块就说明上面4步设置的正确。
设置好了点击测试配置,成功后就设置一个配置名保存这个配置在规则里面使用,
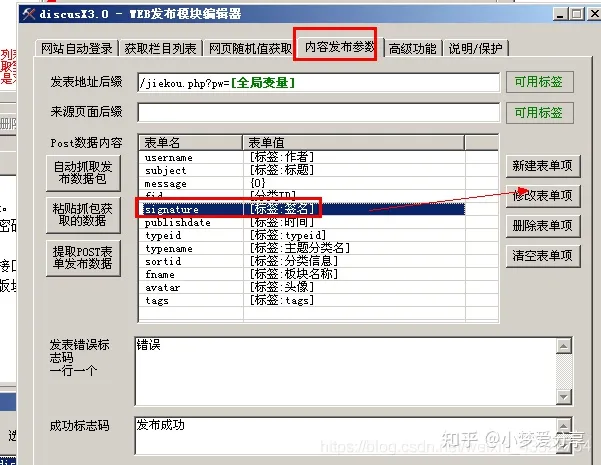
简单分布,只发布标题内容回复的情况
我们打开发布模块,来介绍下里面的内容:
高铁火车头采集器破解版是一款非常好用很受大众喜爱的网络数据采集整理软件。这款软件几乎是所有的网页都可以采集,所涉及的范围非常的广,无论是什么语言还是编码,而且这款软件能力非常的强大。它的收集速度是普通收集器的7倍之多,其中采用了最顶级的配置系统以及经过制作方的反复性能优化,让用户的采集采集速度快到飞起。用户还可以批量的进行任务处理。大大的提高工作效率。有需要的用户快来下载体验吧!

在使用杰奇CMS建小说站的同时,往往会配套使用关关采集器进行采集小说内容,但是关关采集器需要安装在windows系统上,如果想长期建设和维护小说站,对windows系统配置(cpu、内存、硬盘)是有一定的要求,前期投入费用不低。
本文介绍的94采集器是一款杰奇Linux系统采集器,即可以安装在linux上,这样能实现将杰奇CMS和采集器同时安装在Linux上。如果你有一台Linux主机,现在就可以建立自己的小说站啦。
你也可以看看这篇文章,使用杰奇CMS建立小说站对服务器的要求。

下面开始正题,教大家在Linux上安装94采集器。
见顶部
1)下载最新版本94采集器,上传至Linux服务器(94采集器下载在文章底部)
先在自己的Linux上安装宝塔面板,用宝塔面板管理;
将下载的94采集器压缩包上传到服务器上(路径可以自己定)并解压
2)找到config.py文件,修改
只修改端口,94采集器作者反馈其他的不需要修改;端口可以自己定义,只要不被占用即可
![图片[1] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-1.png)
登录宝塔面板–》安全,将上面设置的端口放通
![图片[2] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-2-1.png)
注意:如果你宝塔面板中的安全加固功能开启了,请先关闭,不然管理器启动会失败
1)使用宝塔安装python管理器,并利用管理器安装python3.8.5版本
![图片[3] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-3-1024x128-1.png)
![图片[4] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-4-1.png)
2)添加项目管理
参考下发截图设置
![图片[5] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-6-1.png)
3)启动失败问题
启动失败问题,查看日志,提示缺少cfscrape,解决方法如下:
![图片[6] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-7.png)
到此,94采集器安装完成。
使用Linux的ip加端口的方式登录,如:http://x.x.x.x:9098
默认的登录用户名和密码在config文件;如果修改用户名和密码,修改之后需要重启python项目
![图片[7] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-8-1.png)
如果还有安装问题,可读取这篇文章,下载视频教程。
[b2_insert_post id=”3172″]
当然,如果现有的94采集器无法满足你的要求,你还可以下载 94采集器来修改源码达到自己的目的。
94采集器源码下载地址
[b2_insert_post id=”3748″]
94采集器支持单书号文章采集、书号列表采集、分类列表采集等方式,可以实现对目标站全量、分批采集,完全可以满足个人运营采集的需求。
见上面视频
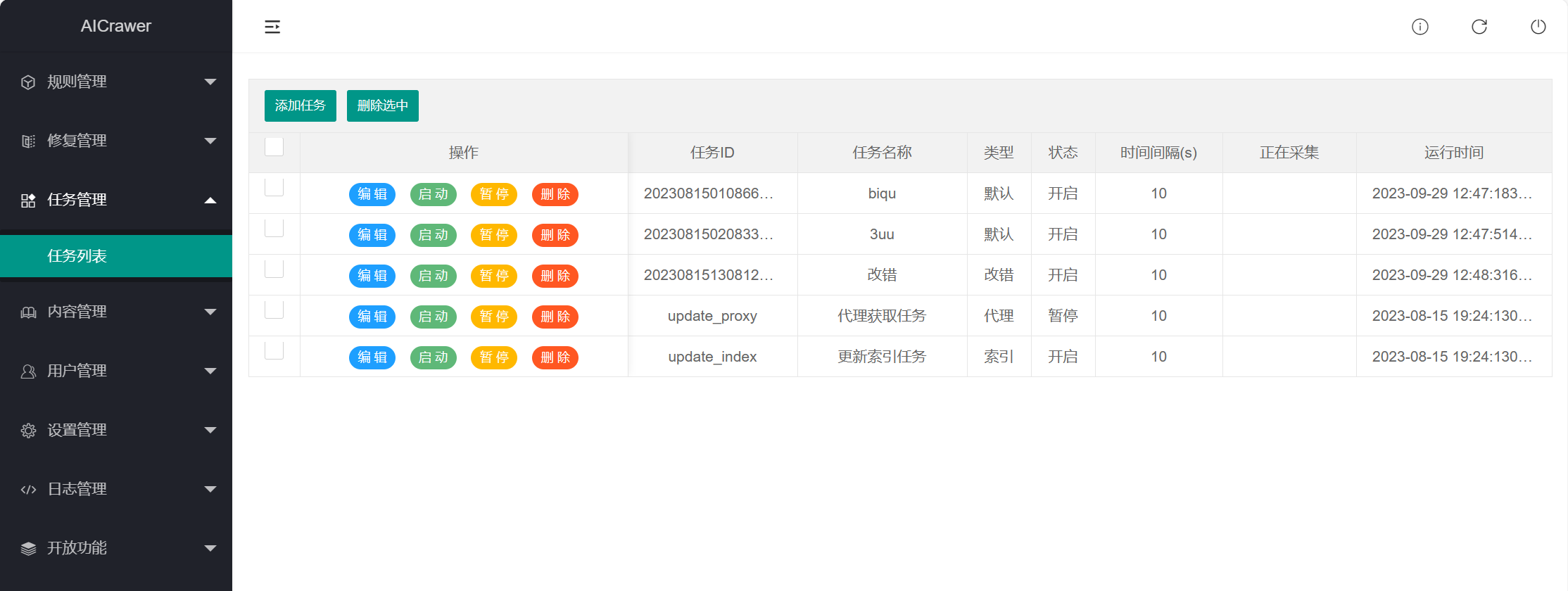
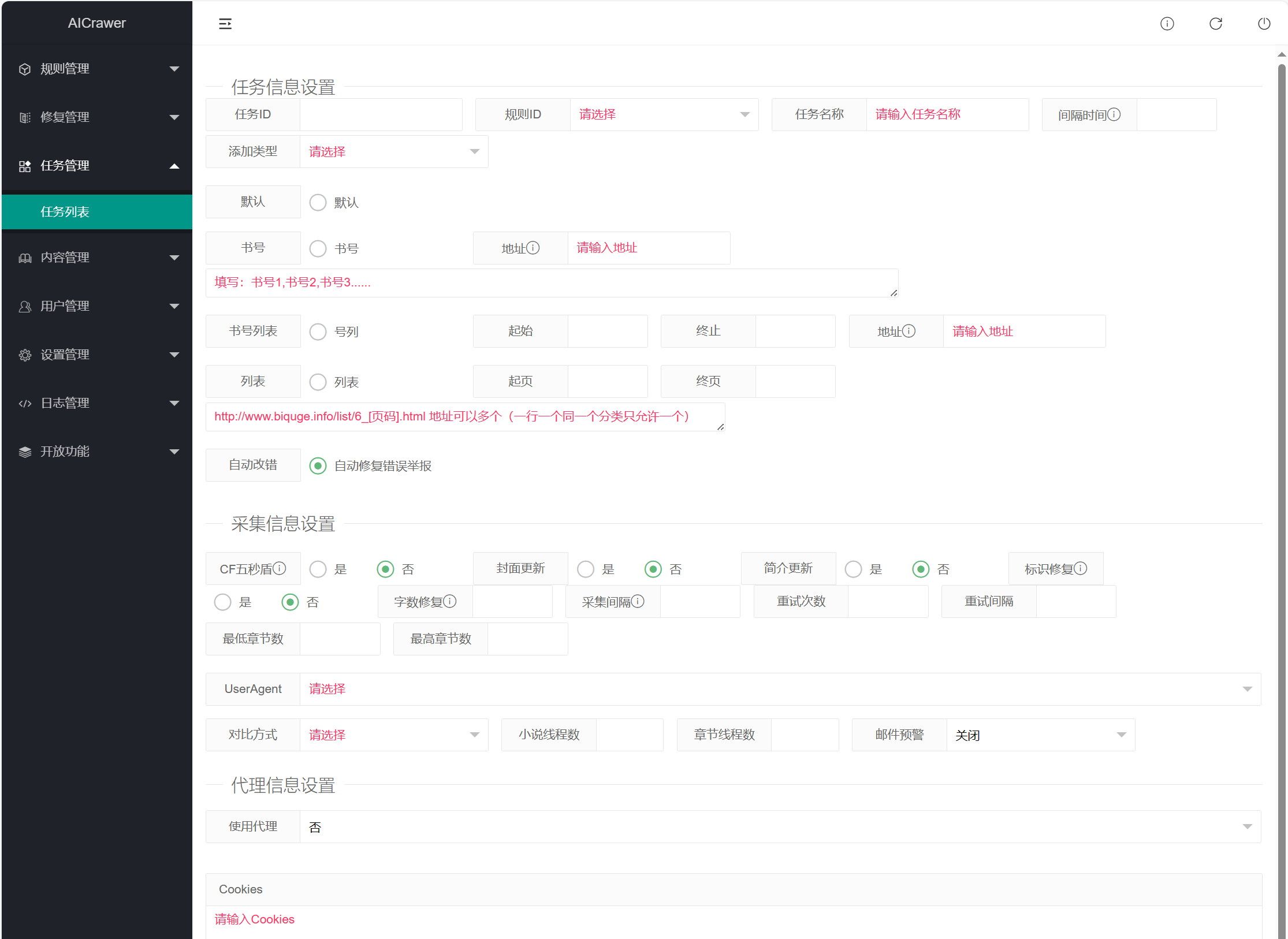
任务ID:空白,后期生成会自动补数据
规则ID:选择采集规则
任务名称:随便写
间隔时间:这里的单位是秒,数据太小,会导致采集源站屏蔽,一般600-1800秒
添加类型:有四个选项,一般默认选“添加” 正常采集
默认、书号、书号列表、列表:这个选择是根据你规则来选择和配置的,这里我们的规则是按照列表来采集的,所以图片中我们只配置了列表,具体设置可以参考自己规则配置。
封面更新:否
简介更新:否
标识修复:是
字数修复:1000
采集间隔:0.1-10
重试次数:5-60
重试间隔:1-30
最低章节数:2 章节数低于2章节的不采集
最高章节数:10000 章节数高于10000章节的不采集
UserAgent:直接选择,因为在配置系统参数的时候已经加入了
对比方式:最后章节名称 按需选择
小说线程数/章节线程数:根据服务器配置写,我是1H1G的测试vps 所以写1-2
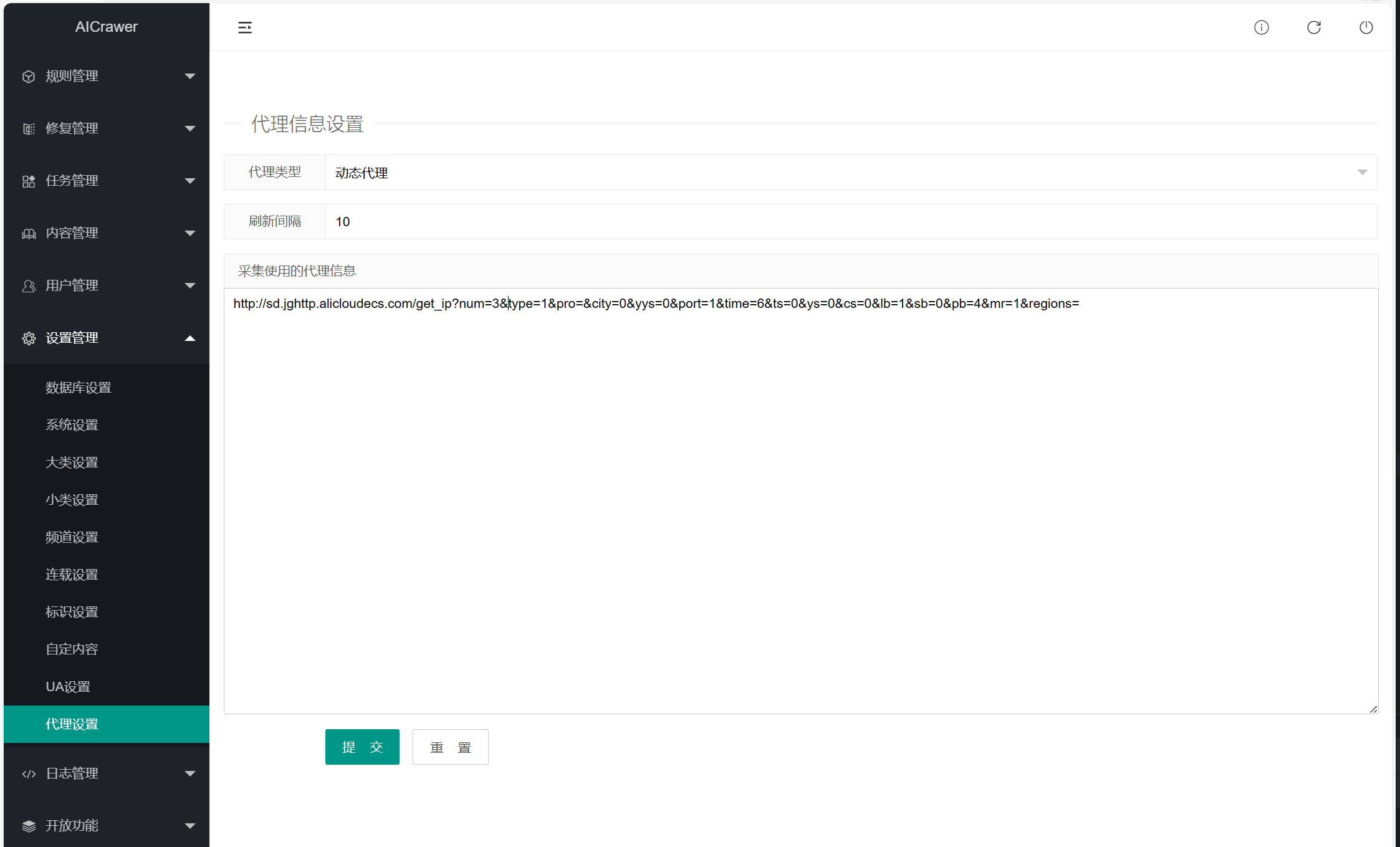
代理信息设置:如果用代理 这里设置
过滤信息设置:如果有不想采集的小说名称,写这里



任务启动,成功采集

小说站94采集器的主要教程暂时就介绍到这里,其他功能大家可以自己测试。整体上来说从安装到设置,再到最后的采集,94采集器的设置还是比较简单的。