源码介绍
YGBOOK全自动采集小说系统 源码已经完美修复各类BUG,所有文件都已经解密完成,深度SEO源码,批量全自动后台采集,并且不需要很大的硬盘即可安装,易云采集了20W本小说占用不到20G,自带4条采集规则,源码压缩包有安装教程,跟着安装很简单的
源码截图

YGBOOK全自动采集小说系统 源码已经完美修复各类BUG,所有文件都已经解密完成,深度SEO源码,批量全自动后台采集,并且不需要很大的硬盘即可安装,易云采集了20W本小说占用不到20G,自带4条采集规则,源码压缩包有安装教程,跟着安装很简单的
1、服务器环境
php5.3.– php7.1 + mysql 5. – MariaDB 10.*
php请加载以下模块
mysql zlib sockets curl iconv mbstring gd
2、更改网站默认编码为uft8,采集GBK自动转为utf8,创建数据库编码为utf8mb4,把sql目录下的jieqi2.4.sql导入数据库,作为网站初始的数据库结构及数据,更改默认存储为INNODB
3、上传网站程序后,以下4个目录必须可写:cache compiled configs files
4、编辑网站目录下 /configs/define.php ,以下数据库参数根据实际填写
@define(‘JIEQI_DB_HOST’,’localhost’); //数据库服务器地址,跟网站在同一服务器时候填localhost
@define(‘JIEQI_DB_USER’,’root’); //数据库登录账号
@define(‘JIEQI_DB_PASS’,’pass’); //数据库登录密码
@define(‘JIEQI_DB_NAME’,’jieqicms’); //网站系统使用的数据库名字
5、默认管理员账号密码:
admin
jieqi.com
6、有彩蛋,能支持到PHP7.3
网站后台 http://www.***.com/admin/
进入后台后可具体设置权限、参数等
正式使用时,请在前台会员中心修改默认的管理员密码
小说分类修改不在后台,请直接编辑 /configs/article/sort.php
6、
网站模板修改规范请参考 http://help.jieqi.com/template/index.html
登录充值接口申请,请参考“登录充值接口.txt”
网站授权设置请参考“软件授权.txt”
电脑版和手机版网站同时安装配置方法:
1、电脑版和手机版网站使用两个独立目录,但是共用数据库和数据文件。默认www为电脑版程序目录,建议绑定域名 www..com;m为手机版程序目录,建议绑定域名m..com
2、编辑手机版网站目录下的 /configs/define.php ,数据库连接设置跟电脑版保持一致
3、如果修改过分类文件 /configs/article/sort.php,请手机版和电脑版保持一致
4、默认程序生成的文件件保存在电脑版网站的 files 目录下,手机版网站也需要读写同一个目录。linux下建议用ls命令建立一个链接把手机站的files目录指向电脑站的files。
windows可以考虑电脑和手机版里面都指定存储目录的绝对路径和访问url,这两个参数在后台 系统管理-系统定义 里面的“数据文件保存路径”和“访问数据文件的URL”。(比如“数据文件保存路径”设置成 E:/web/www/files,“访问数据文件的URL”设置成 http://www.jieqi.com/files)
开源有态度的小说CMS,永久免费
本程序采用MIT协议开源

小浣熊小说cms是一款不以盈利为目的的开源小说cms系统。程序的著作权均归作者所有,用户具有自由的使用权。 如果用户下载、安装、使用本系统,即表明用户信任该系统。那么,用户在使用本系统时造成对用户自己或他人任何形式的损失和伤害,作者不承担任何责任。 本系统只提供做小说系统最基本的功能和程序,未提供任何可以让使用者违法使用、牟利(如侵权盗版、涉黄、非法采集他人数据等)的功能。用户使用本系统从事任何违法违规的事情,一切后果由用户自行承担,作者不承担任何责任。
下载、安装和使用:本系统永久免费,不会盈利,用户可以无限制次数下载、安装本系统。 复制、分发和传播:用户可以无限制次数复制、分发和传播本系统。但必须保证复制、分发和传播的程序的完整性和真实性,需包括所有有关本系统的软件、电子文档, 版权和商标及本协议等。
本系统不含有任何旨在破坏用户计算机数据和获取用户隐私信息的恶意代码;不含有任何跟踪、监视用户计算机功能的代码;不含有监控用户网上、网下行为的功能;不含有收集用户的其它软件、文档中包含的个人信息的功能;不会泄漏用户隐私。 本系统唯一官方下载途径就是GitHub,对于用户从官方途径下载的系统以及从非作者发行的介质上获得的系统,作者无法保证其是否感染计算机病毒、是否隐藏有伪装的特洛伊木马程序或者黑客软件。用户使用此类软件,将可能导致不可预测的风险,建议用户不要轻易下载、安装、使用。作者不承担由此产生的一切法律责任。 用户不得利用本系统误导、欺骗他人;不得故意避开或者破坏作者为保护本系统著作权而采取的技术措施。
聚合采集工具是基于python中scrapy+redis+mysql分布式采集工具的基础上进行开发的一套采集工具.另寄托于docker基础上运行,所以天然支持异步和多机采集工具另外特别方便部署,它采集时会自动入库到mysql数据库,并通过入库的数据进行向远端火车头api发起入库请求.这些操作每天都会定时全自动执行.
1、windows系列,winserver和windows8及以上
2、linux内核系统比如 centos7,ubuntu,macos等系统支持
3、简单讲就是支持docker的系统那就支持
聚合采集工具安装流程我单独增加了linux sh脚本一键式安装,安装过程分为三步
sh docker-install.sh
sh docker-compose-install.sh
cd /opt && tar -zxvf spider.tar.gz && cd /opt/spider && docker-compose up -d
# 爬虫启动推荐使用命令 先执行更新爬虫,再开启爬虫
docker pull jhspider/spider:test && cd /opt/spider && docker-compose up -d
# 爬虫重启推荐使用命令 先执行更新爬虫,再停止爬虫,最后再开启爬虫
docker pull jhspider/spider:test && cd /opt/spider && docker-compose down && docker-compose up -d
# 更新爬虫
docker pull jhspider/spider:test
# 启动爬虫
docker-compose up -d
# 关闭爬虫
docker-compose down
# 重启爬虫
docker-compose restart
# 查看爬虫日志,刚开始时常用该命令去看配置情况
docker logs jh-spider --tail 1000
](https://www.wucuoym.com/wp-content/uploads/2023/03/6350c8606e178.png)
大概效果图如上
这个时候你可以输入docker-compose ps指令查看运行状况

qinqinmh
twhm
qiman
qimiaomh
dmzj 动漫之家
sixmh
xianman
tx550
kuman5
| switch | host | param | type | where | name | |
|---|---|---|---|---|---|---|
| 字段参考值 | 1 | http://www.xxxxx.com | {“api_key”:”hahmh”} | 0 | qiman,tx550,dmzj,kuman5 | 测试发布站点 |
| 字段描述 | 0=关 1=开 | 发布host地址如果没做伪静态要加上http://www.xxxx.com/index.php | api_key里面填写发布密钥 | 类型 0=小浣熊 1=漫城漫画 2=漫城小说 | 指定发布采集源为空则全部发布,这边添加英文漫画源名比如 qinqinmh 如果多项则逗号隔开 | 这个应该都懂的 |
如果没有漫画站可以先用我的做测试,直接复制sql命令并插入即可
INSERT INTO `spider_db`.`publish_site` (`id`, `switch`, `host`, `param`, `type`, `thread_num`, `where`, `name`, `create_time`, `update_time`) VALUES (7, 1, 'http://www.52hah.com', '{\"api_key\":\"hahmh\"}', 0, 2, 'qiman,dmzj', '测试', '2022-11-01 13:42:44', '2022-11-01 13:42:44');
mysql-主机: 127.0.0.1或局域网ip也可外网ip
mysql-用户名: root
mysql-密码: jhspider_pass
mysql-数据库 : spider-db
mysql-端口:33061
redis-主机: 127.0.0.1或局域网ip也可外网ip
redis-用户名: root
redis-密码: jhspider_pass
redis-端口:63791
部署后可自行更改



mac系统 brew install wget
centos系统 yum install wget
ubuntu apt-get install wget最近在搞杰奇cms仿制一个类似笔趣阁的模板,看到它的手机端的时候,其实就知道这个分页肯定是官方版直接调用无法实现的,但是其实只要思路明确的话,利用js可以很好的实现整个效果。原理就是利用jquery根据class获取到分页的那些参数,然后一个for循环直接加进dom层。还算完美,以下是效果图(手机浏览器进入):
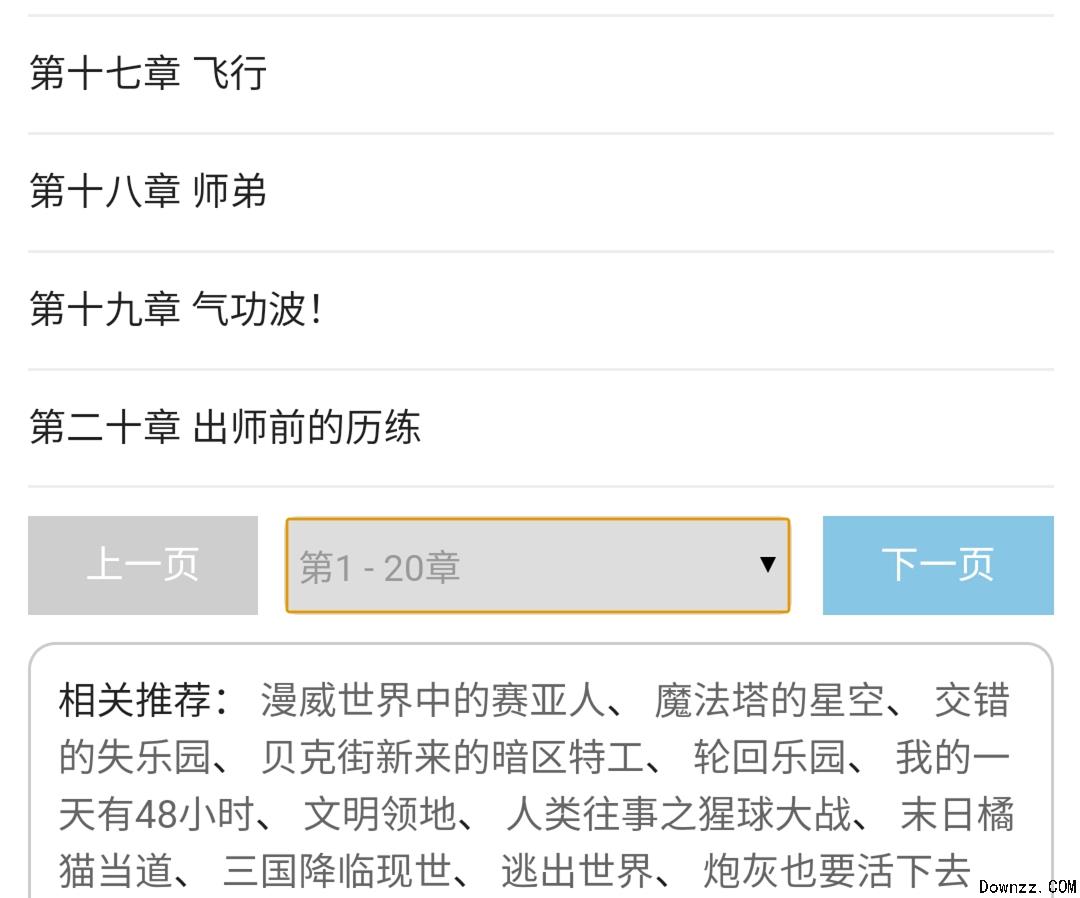

这个界面是完全抓取的现成的模板,所以css样式也是现成的,就不需要自己再去写了,所以如果以后要把17mb那些的手机端,移植到杰奇的官方程序上,这篇教程是很适用的。
总共分为三个部分,这是全部的代码,不过记得要先引入jquery
<div class="listpage"><span class="left"><a class="before" href="javascript:;">上一页</a></span><span class="middle"><select name="pageselect" id="pageselect" onchange="self.location.href=options[selectedIndex].value">
</select></span><span class="right"><a href="javascript:;" class="onclick">下一页</a></span></div>
<div id="pageTo" style="display:none;">{?$url_jumppage?}</div>
<script>
$(function(){
var first = parseInt($("#pagelink .first").text());
var last = parseInt($("#pagelink .last").text());
var page = parseInt($("#pagelink strong").text());
var next;
var prev;
if(page > 1){
var prev = $("#pagelink .prev").attr("href");
$(".listpage .before").attr("href",prev);
}
if(page < last){
var next = $("#pagelink .next").attr("href");
$(".listpage .onclick").attr("href",next);
}
var op = "";
for(var i = 1; i < last; i++){
var k = (i-1)*20+1;
var j = i*20;
if(i==page){
op += "<option value=\"/book/{?$articleid?}_"+i+"/\" selected=\"selected\">第"+k+" - "+j+"章</option>";
}else{
op += "<option value=\"/book/{?$articleid?}_"+i+"/\">第"+k+" - "+j+"章</option>";
}
}
$("#pageselect").html(op);
//alert(op);
});
</script>
1.第一部分是改造原本的分页代码,比如原本的是这样,option标签一路循环下去,上一页下一页也是通过php调用出来的,但是杰奇根本做不到的。

所以,原本的代码就完全精简为如下了:
<div class="listpage"><span class="left"><a class="before" href="javascript:;">上一页</a></span><span class="middle"><select name="pageselect" id="pageselect" onchange="self.location.href=options[selectedIndex].value">
</select></span><span class="right"><a href="javascript:;" class="onclick">下一页</a></span></div>
这样的意思是,无论是上一页,下一页,还是中间的下拉选项全部都留空了,不给任何值,因为所有的值将交给js处理,让js将杰奇原本的分页代码转进去。
2.放置杰奇的原本分页代码,但是默认隐藏起来。
<div id="pageTo" style="display:none;">{?$url_jumppage?}</div>
这句代码,在实际网页访问中,会输出所有的分页和上一页下一页那些,但是不是按照模板需要格式来的,而且二开也特别麻烦。所以默认隐藏了,不过如果看源代码视图,就会发现它的关键值都是有class的,所以完全能让js来读取。

3.利用js读取原本的分页代码关键词,然后生成html代码,渲染进分页的代码中。
<script>
$(function(){
var first = parseInt($("#pagelink .first").text());
var last = parseInt($("#pagelink .last").text());
var page = parseInt($("#pagelink strong").text());
var next;
var prev;
if(page > 1){
var prev = $("#pagelink .prev").attr("href");
$(".listpage .before").attr("href",prev);
}
if(page < last){
var next = $("#pagelink .next").attr("href");
$(".listpage .onclick").attr("href",next);
}
var op = "";
for(var i = 1; i < last; i++){
var k = (i-1)*20+1;
var j = i*20;
if(i==page){
op += "<option value=\"/book/{?$articleid?}_"+i+"/\" selected=\"selected\">第"+k+" - "+j+"章</option>";
}else{
op += "<option value=\"/book/{?$articleid?}_"+i+"/\">第"+k+" - "+j+"章</option>";
}
}
$("#pageselect").html(op);
//alert(op);
});
</script>
读取了第一页的数字,最后一页的数字,当前页的数字,并且知道每页输出20个,于是就可以把这些值处理后赋值到分页代码中,而被删除的option标签对,也就由js生成,一起放进select中了。有i和j这两个字段,就是显示多少章到多少章,简单的计算公式就可以实现。
是不是思路一下子就清晰了。
在采集回来的小说中,有时候简介里会采集有不希望出现的字符串,例如规则没写好导致采集到了html代码,例如出现了采集目标站的域名等。
只需要在杰奇后台的数据库升级或者使用PHPMyadmin管理器中执行下面的SQL,就可把指定的字符串替换成你想要的字符串。
SQL语句如下:
update `jieqi_article_article` set intro = REPLACE(intro,'指定字符串','替换进去的字符');举例要把简介中的</p>替换成空:
update `jieqi_article_article` set intro = REPLACE(intro,'</p>','');
杰奇cms模板章节页的标题前有个空格怎样去掉?有用户反映用杰奇程序做的站章节页的标题前面多了一个空格,如下图:

查看模板在章节名称前没有添加空格,引起这个问题的原因是杰奇程序给章节名称前面预留了分卷名,分卷名和章节名中间需要有个空格分隔开,如下图:

解决方法是找到/modules/article/class/package.php文件,找到如上图代码位置
$jieqiTpl->assign('jieqi_title',$volume.' '.$chapter);把空格去掉,如不需要显示分卷也可以把分卷名变量去掉。
杰奇小说连载系统1.70安装程序,内含模块有:小说连载、论坛。
1.7是用户量最大也是最稳定的一个版本,模版也是最多的一个版本,采集器也是比较完善的。
其他版本或多或少,都没有这个版本好用。
强烈建议小说站还是用这个版本。