一、前言
最近有朋友问我,某个视频网站也是阿里ts加密方式。恰巧51假期,就拿来分析一番,一看代码与之前某视频网的加密方法几乎完全一样。唯一不同的是 AES解密时逻辑稍有不同。还有一些奇怪的问题,同时发现,自己写过的代码,自己都已经不理解了,之前吾爱发的解密文章,被xx了,综合种种吧,冒出了写此文,算是一个复习,同时把方法分享给大家。此外,前些日子有个朋友在帖子中提到了PES解密的问题,希望此文也可以帮助到他。@VOOV
二、TS文件结构概述
1、几个基本概念
ES流(Elementary Stream) 基本码流,不分段的音频、视频或其他信息的连续码流。
PES流 把基本流ES分割成段,并加上相应头文件打包成形的打包基本码流。PES是打包过的ES,已经插入PTS和DTS,一般一个PES是一帧图像。
TS流(Transport Stream) 传输流,将具有共同时间基准或独立时间基准的一个或多个PES组合(复合)而成的单一数据流(用于数据传输)。
其数据内容可包含视频、音频、字幕等数据。将一个视频切成多个ts文件,实现视频的分段传输。多用于电视媒体。
2、ts文件格式
ts文件由ts数据包组成,每个包大小为188字节(或204字节,在188个字节后加上16字节的CRC校验数据,其他格式一样),每个数据包存储的内容可能不同,可能是视频、音频、字幕,或索引表信息,索引表就类似于一本书的目录,通过目录,就可以找到需要的章节,章节就类似于视频或音频等数据。
注:本文所描述的ts包,均为188字节。
ts数据包 由 4字节包头、附加数据(一般用来填充,为了满足188字节)、负载数据(即PES的部分数据)如下图: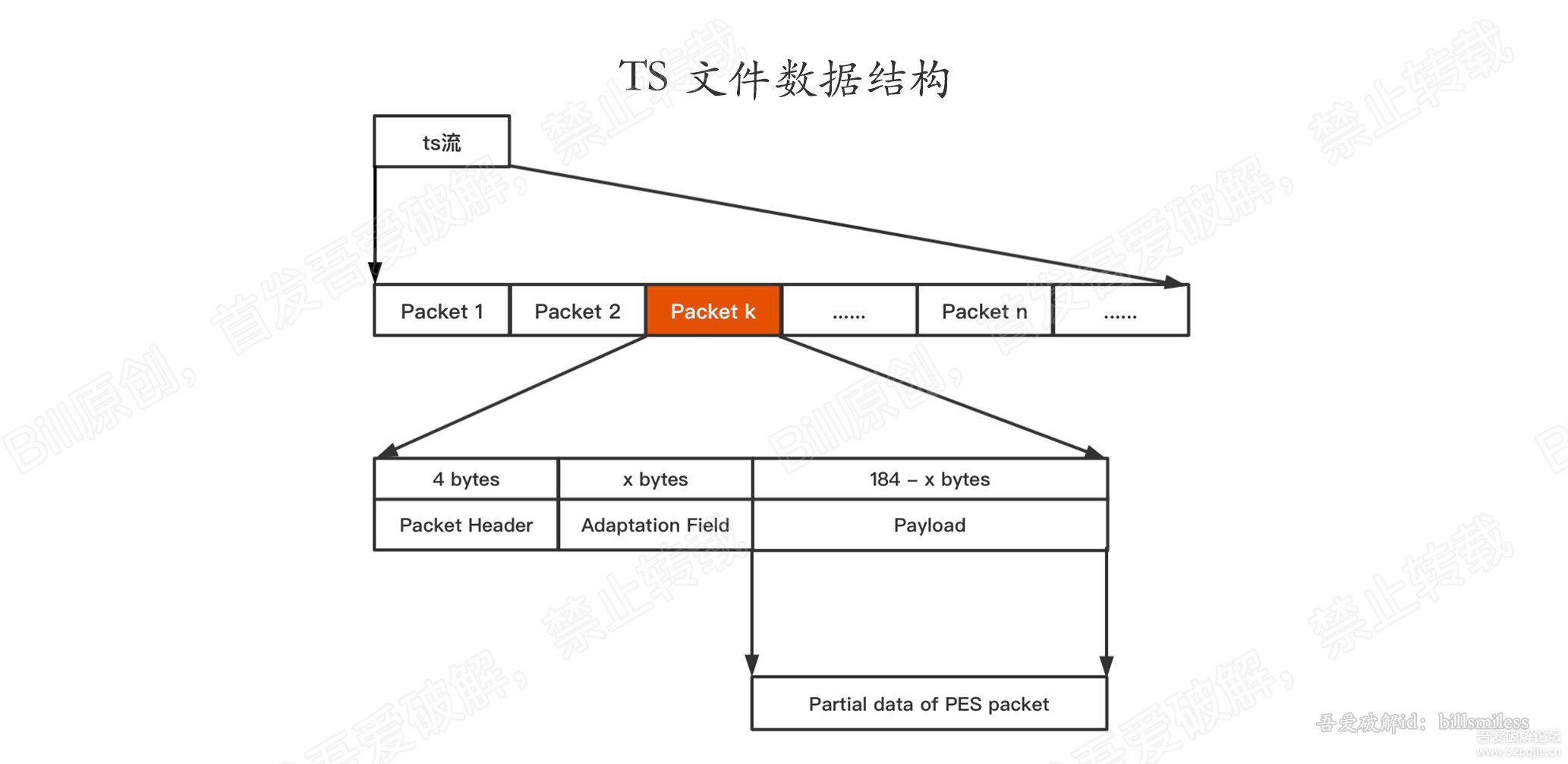
一个完整的PES包数据,可能存在于多个ts数据包中,也就是说,一个ts包中,可能含有pes包的包头,也可能仅仅含有pes包的负载数据.
下图展示了,PES包是如何转为TS包的。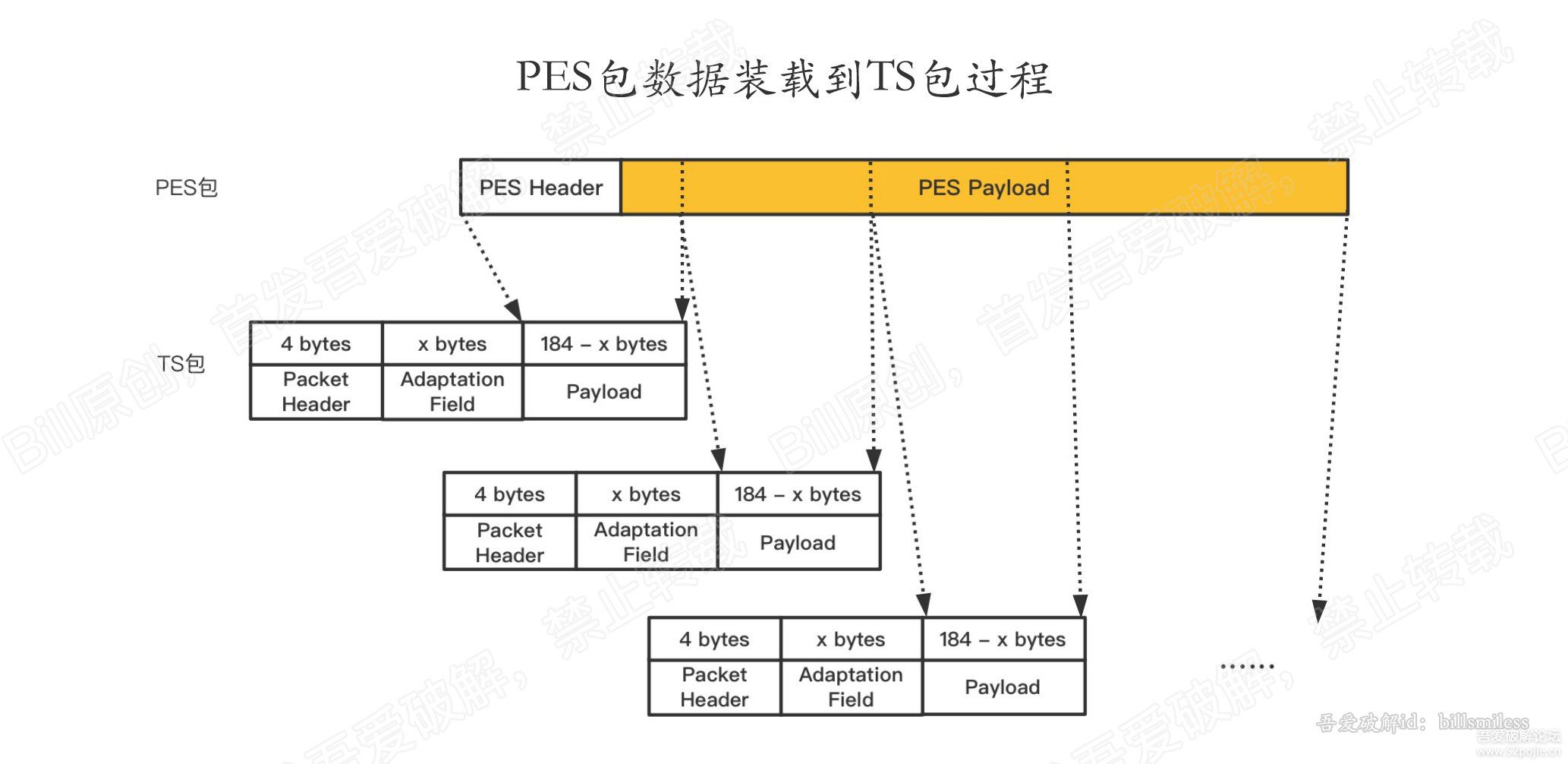
下面来分析占4字节(32比特)ts包头的结构以及附加域(长度不定)的结构。先上图。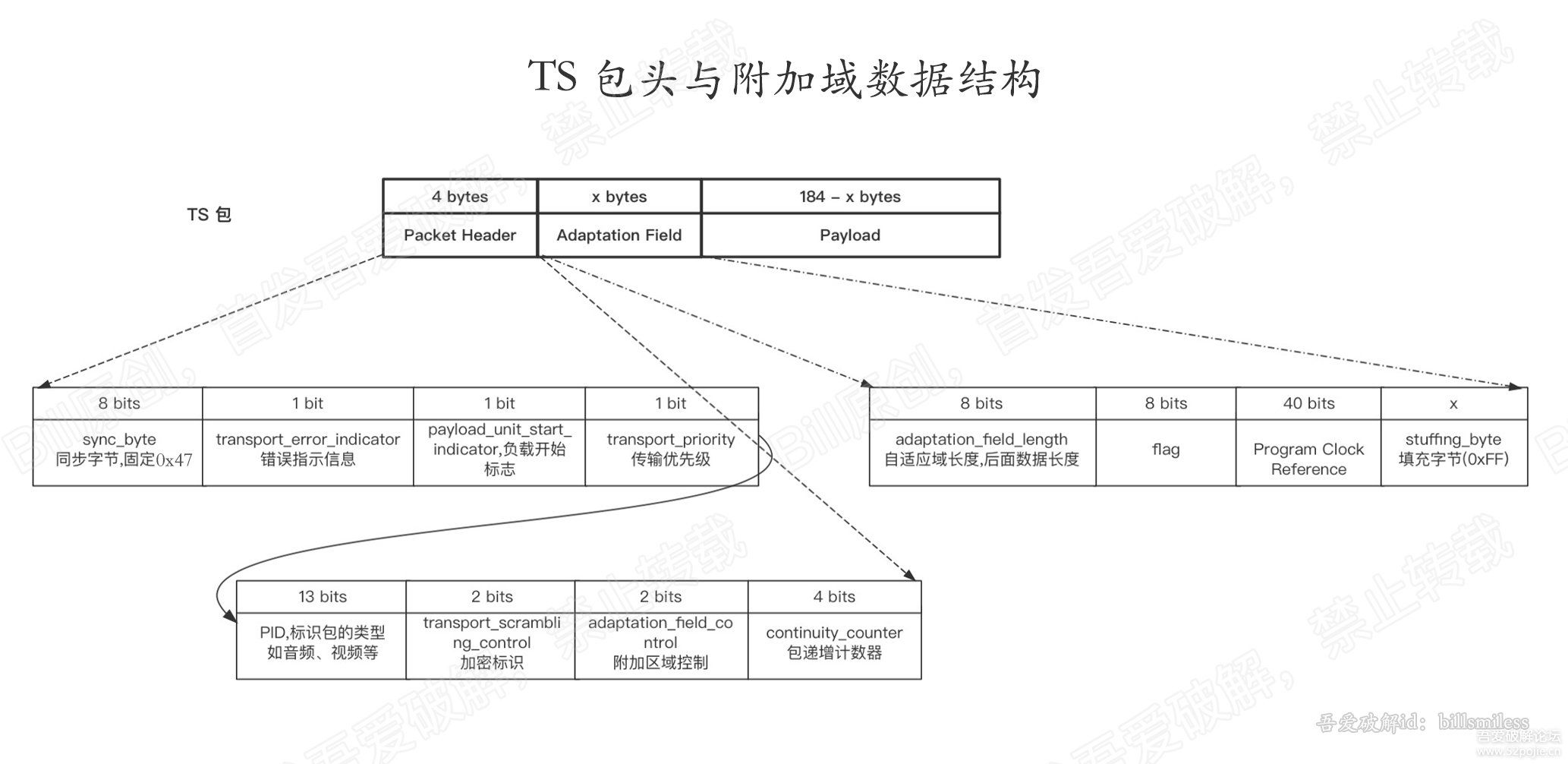
这里我们仅分析我们用到的字段,其中头中用到4个字段值,附加域只用到长度字段。如下表。
| 序号 | 标识 | 位数 | 说明 |
| 0 | sync_byte | 8 bits | 同步字节,固定是0x47 即每个ts包的首字节都是0x47 |
| 2 | payload_unit_start_indicator | 1 bit | 负载单元开始标识 用来判断是否是pes包的起始包 若为0,则表示非起始包。 非PES起始包,不含有PES包头 |
| 4 | PID(Packet ID) | 13 bits | ts包的数据类型 ts包有几种数据类型: PAT、PMT、音频、视频、字幕等 |
| 6 | adaptation_field_control | 2 bits | 附加域数据标识,有如下值: 00:供未来使用,出ISO/IEC所保留 01:无adaptation field,仅有效载荷 10:仅有Adaptation field,无有效载荷 11:Adaptation field后,带有效载荷 翻译下: 因为ts包长度固定188字节,因此 若附加域数据过多,就会无法装载payload |
| 附加域中的字段 | |||
| 0 | adaptation field length | 8 bits | 自适应域长度,后面数据长度 除去本字段外,附加域其余字段的长度 |
表中提及的PAT、PMT相当于一本书的目录,PAT相当于目录的目录,通过他们就可以找到某视频的位置。
PAT的pid为0,首先我们就会分析PAT。
接下来分析下PES头的数据格式。为我们后面解密做铺垫。先上图。
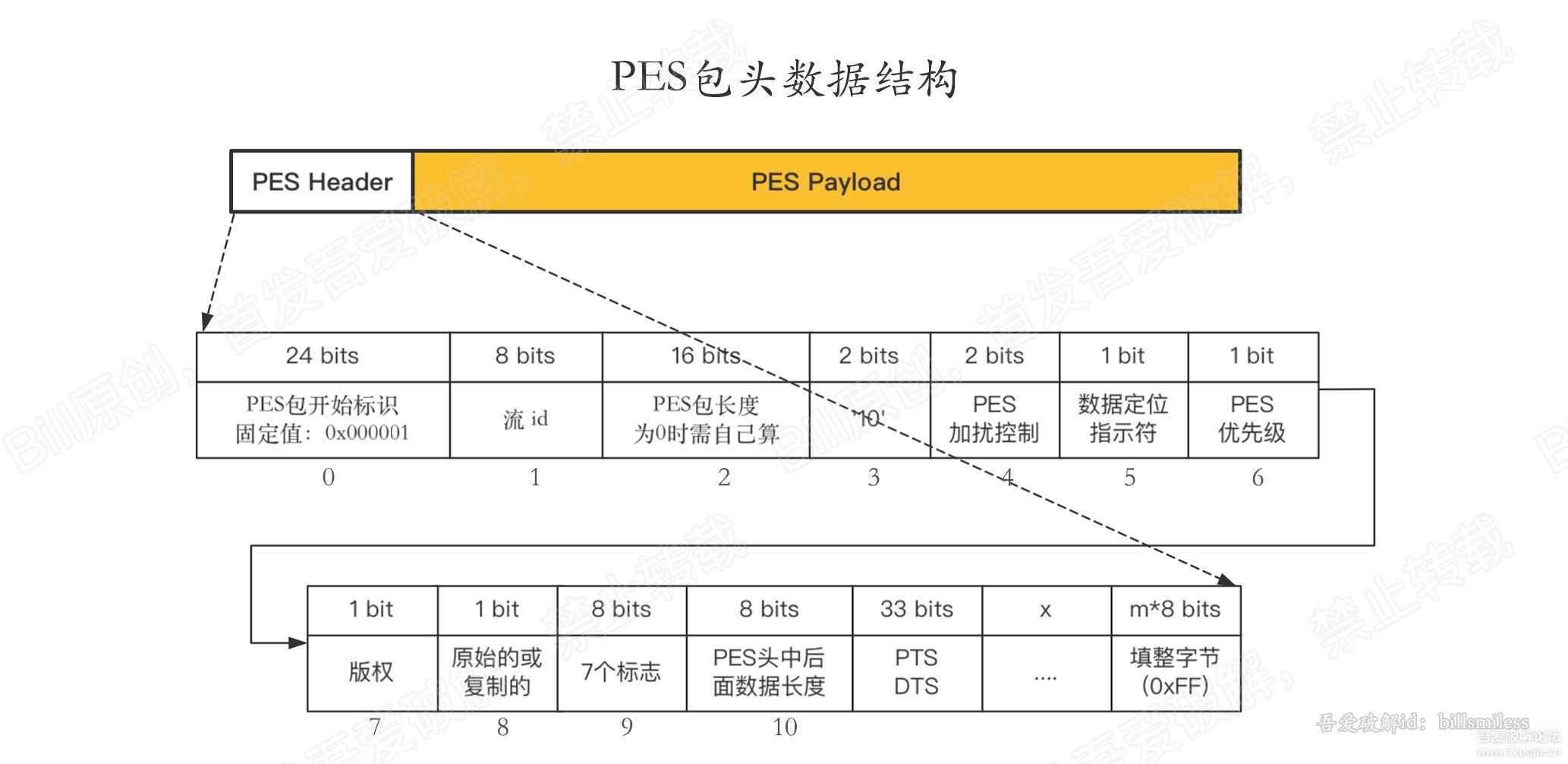
字段很多,只分析我们需要的字段。如下表:
| 序号 | 标识 | 位数 | 说明 |
| 0 | pes开始标识 | 24 bits | pes包开始标识 固定值:0x000001 |
| 10 | PES头中后面数据的长度 | 8 bits | pes头后面字段的长度 pes头的长度就等于: 本字段以及之前所有字段的长度 加上本字段的值 |
这里其实只要拿到pes头数据的长度。显然通过第10个字段,就可以计算出pes头的长度了。
以上知识点,就可以支撑我们继续分析ts文件的加解密了。
三、ts加密分析
结合代码,我们分析下加密的逻辑。
为了便于调试,这里我用未解密的video.ts文件作为样例,以及自己写的解密demo,来分析。
(关于demo以及源代码等,我会放在文末)
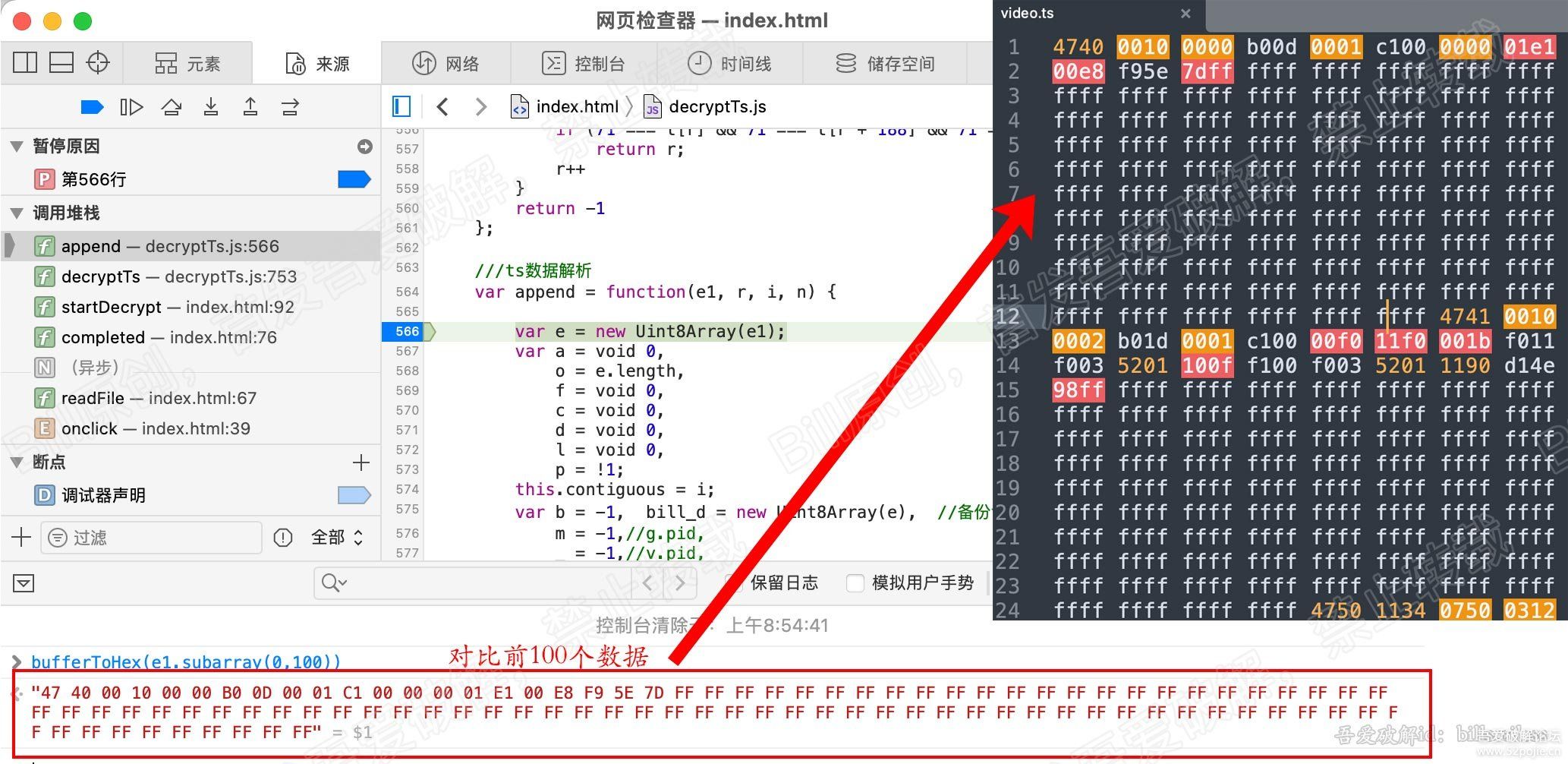
用其他软件(我用SublimeText)以16进制的形式,打开video.ts。
这个一直开着,用来与代码读取的数据进行对比。看我们代码读的数据是什么。为什么这么读。
a、首先找到ts文件数据解析函数。这里就是append(…)函数。(关于如何定位此函数,请参考我之前的文章)
运行demo, 输入key,导入ts。提前在append函数首行打上断点。点击开始解密。会进入我们的断点。
接下来看下我们传入的ts数据。
以16进制的形式打印e1的值,与我们的video.ts数据对比,是一致的。
看下图(此步骤,没啥意义,就是为了找找感觉)
继续,在587行 C = syncOffset(e); 代码处添加断点,继续执行,程序会停留在此断点。
此函数是在找 ts包的起始偏移,因为每个ts包都是188字节,
所以此函数就通过判断连续3个188字节的首字节是否是71(16进制0x47), 若是则确定此索引为起始索引。
我们这里都是0,也就是ts文件的第一个字节就是0x47,细心的朋友,已经发现了。
接下来进入循环开始解析ts数据了。注意代码中 bill开头的函数与变量,是用来解密的。暂时忽略。
在638行,也就是for循环的第一行,加断点,继续执行,会停在这里。我们分析下for循环的条件。先看看图。
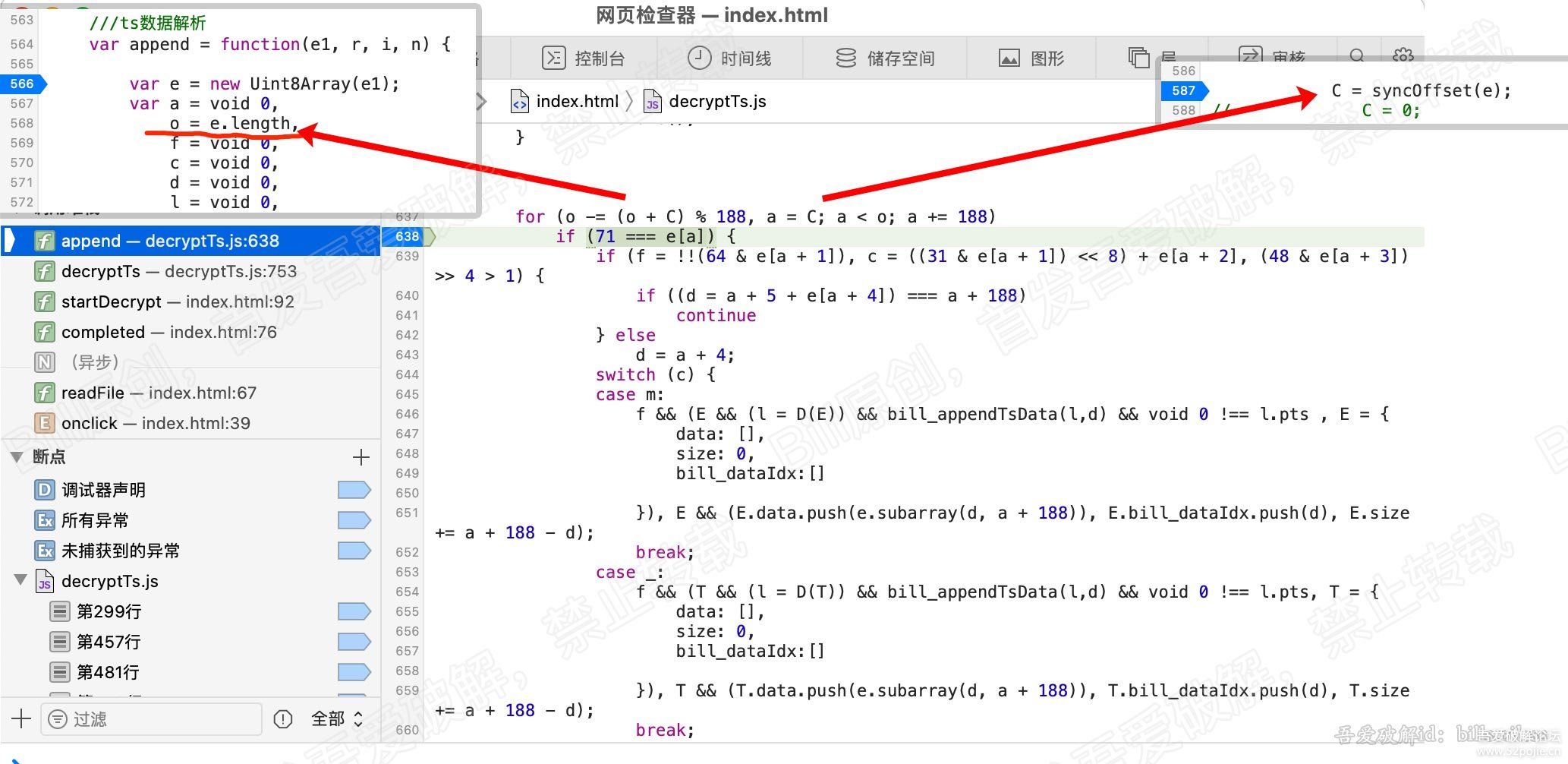
看637行的for循环
for (o -= (o + C) % 188, a = C; a < o; a += 188)这里C是587行同步偏移返回的值,我们这里都是0。所以for循环就等于以下:
for (o -= o % 188, a = 0; a < o; a += 188)这就清晰多了
这里只有2个变量,a和o,a初始值是0,然后每次循环累加188,看看o是哪里来的。
在本函数的第三行,也就是568行,看到 o = e.length, e在上一行,就是我们ts数据的uint8数组。
因此,o就是ts数据的总长度, 那么o -= o % 188,是什么意思?
先用总长度对188取余,然后总长度再减去余数, 也就是说,是为了保证我们循环总长度为188的整数倍。
为什么这么做?是为了循环体内,不出现数组越界情况。(循环内部会分析)
延伸下,这里循环结束后,取余出去的那部分数据不就没有分析到了嘛。
所以当循环结束后,还得解析取余出去的那部分数据。这样整个ts文件数据就都被解析到了。
继续,看638行的 if (71 === e[a]) ,显然这是在判断ts包的首字节是否为71(71是十进制,16进制0x47)
如果首字节是0x47,则分析此包数据。否则直接报错。
此时a为0,那么我们看看e[0]的值,确实是71。
去之前打开的video.ts文件,看看第一个字节是不是0x47。一定是的。
目前,我们是在video.ts文件的第一个字节处,也就是第一个ts包。此时方便我们查看本地的video.ts的数据。
所以结合ts文件格式和代码,我们分析下一段代码,就是 639->643行间的 if…else…
先来看 639行:
if (f = !!(64 & e[a + 1]), c = ((31 & e[a + 1]) << 8) + e[a + 2], (48 & e[a + 3]) >> 4 > 1)好家伙,看着就懵逼的感觉。
可以看到,if条件内,有3个语句,逗号分割,当最后一个语句为真时,就会进入if内部。
也就是说,前2个语句,就是执行下,跟if条件没啥关系。那也得分析😄
先来看第一个语句
if (f = !!(64 & e[a + 1]), c = ((31 & e[a + 1]) << 8) + e[a + 2], (48 & e[a + 3]) >> 4 > 1)叹号取反,双叹号就是负负得正。等于没有。所以只看: 64 & e[a + 1]
我们知道a是0,那么e[a+1],显然就是video.ts的第二个字节的值。
我们可以看到,e[1]的值也为64 , 然后再 与 64 进行与运算。
我们把64都转为2进制(1个字节8bits, 所以补足8位)
64: 0100 0000
64: 0100 0000
然后进行与运算。
可以发现和64进行与运算的目的,就是取 取本字节8位中的左起第二位。
该bit就是ts头中的第9位(0开始),前面我们分析过 ts头的第9位是payload_unit_start_indicator,
即负载标志位。判断本ts包的负载数据是否是pes的起始包。
(不理解的话,可以翻阅ts文件结构概述章节)
因此我们可以知道
f 即判断本ts包的数据是否是pes的起始包。(若是起始包,包含pes头)
若是起始包,则f为1,否则0
继续看第二个语句:
直接翻译下:
把 第二个字节的值 和 31 进行与运算,然后左移8位,再和第三个字节值 相加。
分析过程省略,大家自行操作。
上结果,c的值就是 ts头中占有13个比特的pid。
pid代表了ts包的数据类型,可以是音频,视频、PAT、PMT或其他
c = ((31 & e[a + 1]) << 8) + e[a + 2]
此时的pid,不用看,一定是0,0代表是PAT。
这里再介绍下PAT与PMT。
PMT存储了媒体的目录信息,哪个视频在哪里,哪个是音频等
PAT则是存储了PMT的信息,PMT在哪之类的。
因此一开始一定是先解析PAT,通过PAT找到PMT,解析PMT找到我们需要的 音视频数据。
继续看第三个语句:
(48 & e[a + 3]) >> 4 > 1翻译:
第四个字节和48进行与运算,右移4位,然后看是否大于1
分析略,直接上结果:
给(48 & e[a + 3]) >> 4 起个名字叫k吧,
k的值就是 ts包头的32位占2bits的 adaptation_field_control,附加区域控制字段。
该字段的值,用来判断附加区域是否存在,大于1 表示存在 附加域。(具体可看上一章节)
由此,我们可以知道,只要存在附加域,就会进入if内部。
若不存在附加域,则执行else,稍后分析。
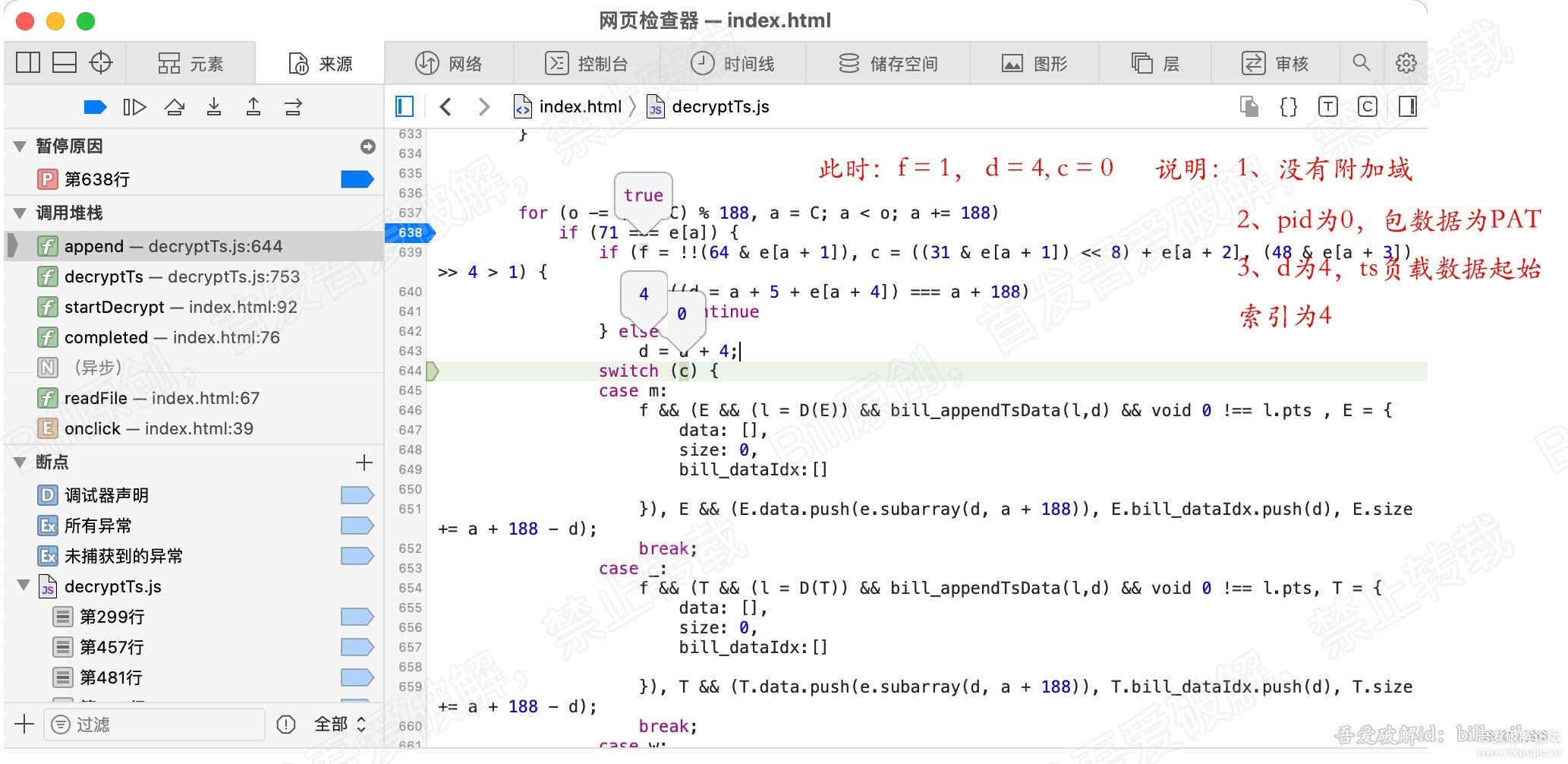
先来看if内部,也就是640行:
if ((d = a + 5 + e[a + 4]) === a + 188)因为此时,a=0,所以简化下d的等式:
d = 5 + e[4] === 188
翻译下: ts的第5个字节值加上5。
我们知道ts的头是4个字节,并且此时在if内部,即是存在附加域的。
因此 我们去上一章节 看下附加域的数据格式,可以知道:
第一个字节(8bits)代表的是adaptation_field_length, 即附加域后面的数据长度。就是此字节后面的数据长度。
那么再加5,就表示算上 4字节的ts头长度,以及 adaptation_field_length 所占的1字节。
也就是说 d = 5 + e[4] 的值,就是 ts头长度 和 附加域长度 之和,
那么和188比较是为什么? 因为ts包的总长度为188,当ts头和附加域的总长度已经达到188时,就不会存在负载数据了,
所以就不必继续分析此包,直接 continue,继续下一个包解析。
好,接下来看看else代码,就一行,643行:d = a + 4;
相信大家应该能猜到了。这里的4就是ts头的长度,d = a + 4,d 即表示ts负载数据的起始索引了。
综上, 简单总结下这个if … else …
1、f: 计算ts包的负载数据是否是pes的包的起始包。
2、c: 计算ts包的pid
3、判断是否存在附加域,若存在计算附加域和ts头的总长度。得到ts负载数据的起始索引d的值。
4、若不存在附加域,则 ts负载数据的起始索引 d 的值为:包起始索引 + 4(ts头的长度)。
结论:f表示是否是pes起始包, c代表pid, d表示ts包负载数据的起始索引。
f、c、d 后面会一直用。 如下图:
接下来就是 switch 语句了。
switch (c) {
case m:
f && (E && (l = D(E)) && bill_appendTsData(l,d) && void 0 !== l.pts , E = {
data: [],
size: 0,
bill_dataIdx:[]
}), E && (E.data.push(e.subarray(d, a + 188)), E.bill_dataIdx.push(d), E.size += a + 188 - d);
break;
case _:
f && (T && (l = D(T)) && bill_appendTsData(l,d) && void 0 !== l.pts, T = {
data: [],
size: 0,
bill_dataIdx:[]
}), T && (T.data.push(e.subarray(d, a + 188)), T.bill_dataIdx.push(d), T.size += a + 188 - d);
break;
case w:
f && (A && (l = D(A)) && bill_appendTsData(l,d) && void 0 !== l.pts , A = {
data: [],
size: 0,
bill_dataIdx:[]
}), A && (A.data.push(e.subarray(d, a + 188)), A.bill_dataIdx.push(d), A.size += a + 188 - d);
break;
case 0:
f && (d += e[d] + 1), S = R(e, d);
break;
case S:
f && (d += e[d] + 1);
var O = k(e, d, true, false);
m = O.avc, m > 0 , _ = O.audio, _ > 0 , w = O.id3, w > 0 , p && !b && (p = !1, a = C - 188), b = !0;
break;
case 17:
case 8191:
break;
default:
p = !0
}我们前面分析知道 c 就是pid, 因此,switch,就是根据pid来进行解析不同数据包。
看下 switch的case值:
case m: , case _: , case w: , case 0:, case S:, case 17:, case 8191: , defalut:
只有 m 、_ 、w 、 S ,4个变量的未知。
我们知道此时 c的值是0, 会进入 case 0 分支的代码,
此处是解析PAT,S = R(e, d); 得到S的值。
看S分支的代码,我们可以看到其中会给 m,_,w 3个变量赋值,其实S是解析PMT。
PMT解析完,就得到了 其他3个case 分支的值,我们继续看其他 case m,_,w 分支的代码,
非常像,只是变量不同。通过分析知道,此3个分支就是解析加密数据的部分。在此不再叙述。
接下来就分析这3个分支的一个, 就选第一个case m
直接在case m 分支内部第一行打断点,即646行,其他断点全部过掉,然后继续执行。程序停在了646行。
分析下变量的值:
首先分析:f,表示是否是pes起始包。 此时的f的值一定是 1(true),为什么?
因为我们是第一次进入m分支,说明我们第一次解析pid为m的类型ts包,第一次解析此包,说明它一定是pes的起始包。
所以 f 一定是1, 结合上一章节pes包在ts包中的装载格式,就会明白,pes的包被分割到不同的ts中,
那么切割到第一个ts 包中的pes数据,一定包含pes的包头,所以该ts的 f 值一定是1 。如下图:
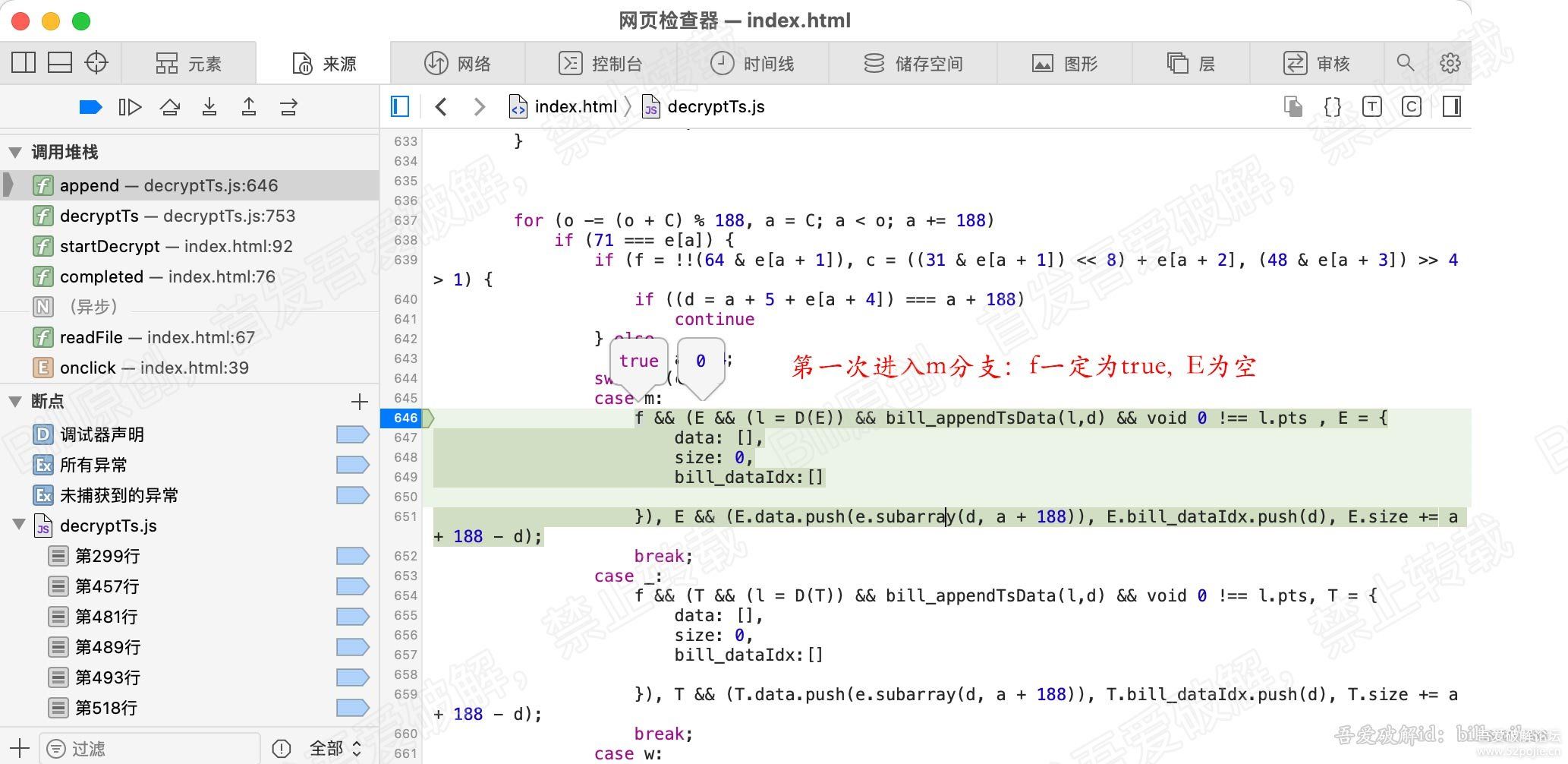
f 是1 ,就会继续执行f后面的代码。
接下来一行一行分析下 case m 的代码。bill_开头的代码,暂时过滤,是解密用的。
case m:
f && (E && (l = D(E)) && bill_appendTsData(l,d) && void 0 !== l.pts , E = {
data: [],
size: 0,
bill_dataIdx:[]
}), E && (E.data.push(e.subarray(d, a + 188)), E.bill_dataIdx.push(d), E.size += a + 188 - d);
break;有两个语句以逗号分割,两个语句之间是依次执行。
分析语句1:
f && (E && (l = D(E)) && bill_appendTsData(l,d) && void 0 !== l.pts , E = {
data: [],
size: 0,
bill_dataIdx:[]
})
翻译以下:
当 f 为真时, 若E 有值,则执行 (l = D(E)) && bill_appendTsData(l,d) && void 0 !== l.pts,并给E重新赋值
若E 为空,则直接给E赋值
当 f 为假时, 后面代码不会执行,语句1结束
这里 l = D(E), 此代码将加密的PES数据解密,返回给l
分析语句2:
无论语句1如何执行,语句2都会执行。
E && (E.data.push(e.subarray(d, a + 188)), E.bill_dataIdx.push(d), E.size += a + 188 – d);
若E 为真,则给E的data添加 e的索引d到a+188之间的数据, 给E的size累加值: a + 188 -d ,这是刚才添加数据的长度。
若E 为空, 则结束
我们知道 d是 ts包负载数据的起始索引,d > a, a是ts包的起始索引。所以 e.subarray(d, a + 188),这个数据,就是ts包的负载数据。
因此语句2的目的就是:将ts包的负载数据添加到 E.data中,同时记录下添加的数据的总大小。
我们将语句1和2一起翻译下:
当f为真时,即ts包负载是pes的起始包,若E为存在值,则直接去解密E的数据,返回给l,
接下来则给E重新赋值,然后将此时ts的负载数据,添加到E.data中,并记录总大小size
当f为假时,即ts包负载不是pes的起始包,将此时ts的负载数据,添加到E.data中,并记录总大小size
我们可以发现规律,只有当 f 为真时且E数据存在,会去解密pes数据,且解密的数据是 f为假时, 添加到E.data中的数据。
由此,我们可以得出,加密的数据是一个完整的PES数据,(PES头未加密,需要在pes解析中分析才能知道)。且这些PES数据存在于多个ts包中。
接下来分析PES解密函数:l = D(E)
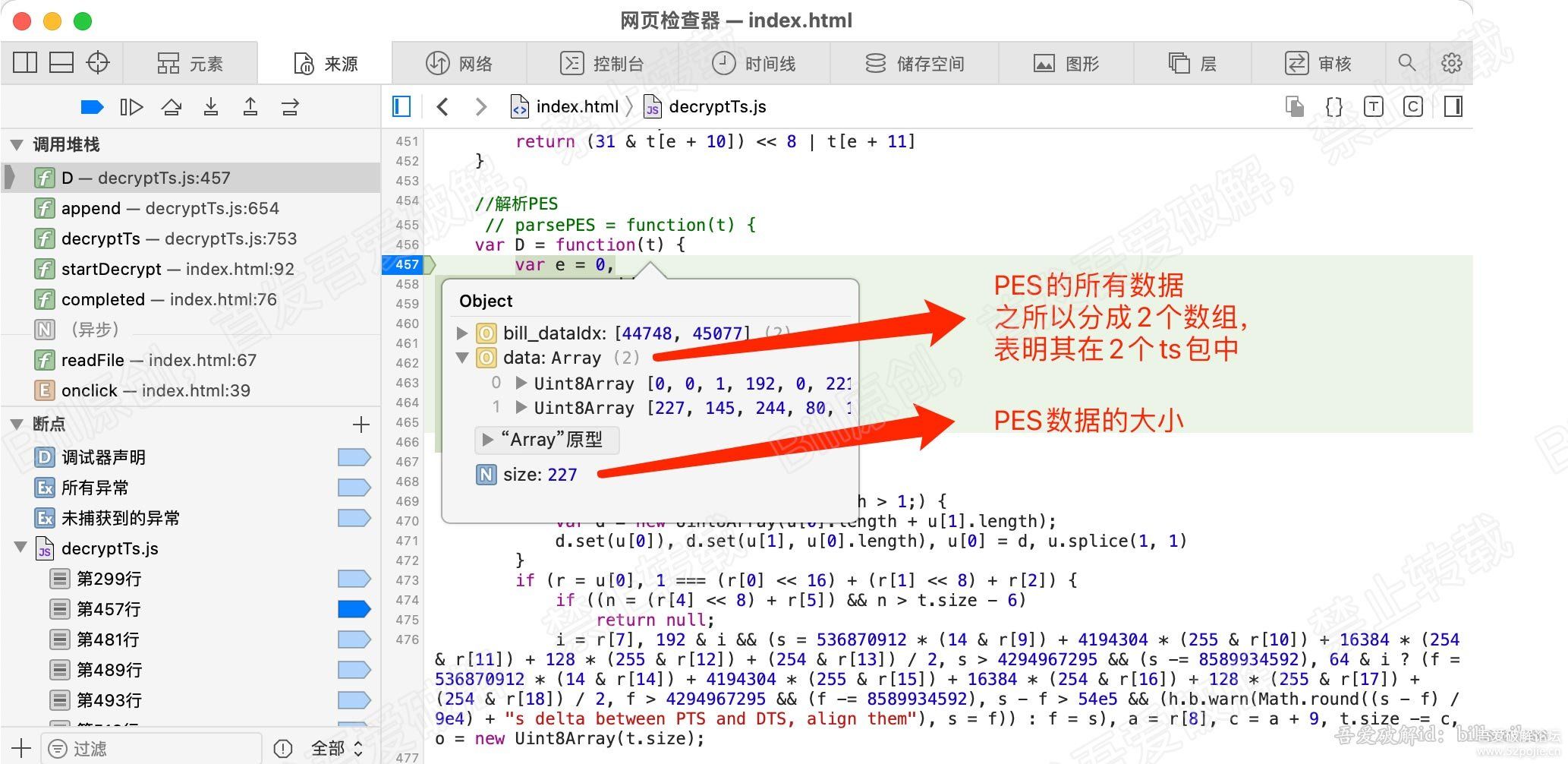
在此函数的第一行,即:457行,打断点,删除其他断点,继续执行。会停留在此处。
查看下传进来的参数t的值,其实就是上个函数的E的值,发现有size与data。
其中data即pes的数据,data是个数组,数组内的元素其实是 存在于各个ts包中的pes数据。看图:
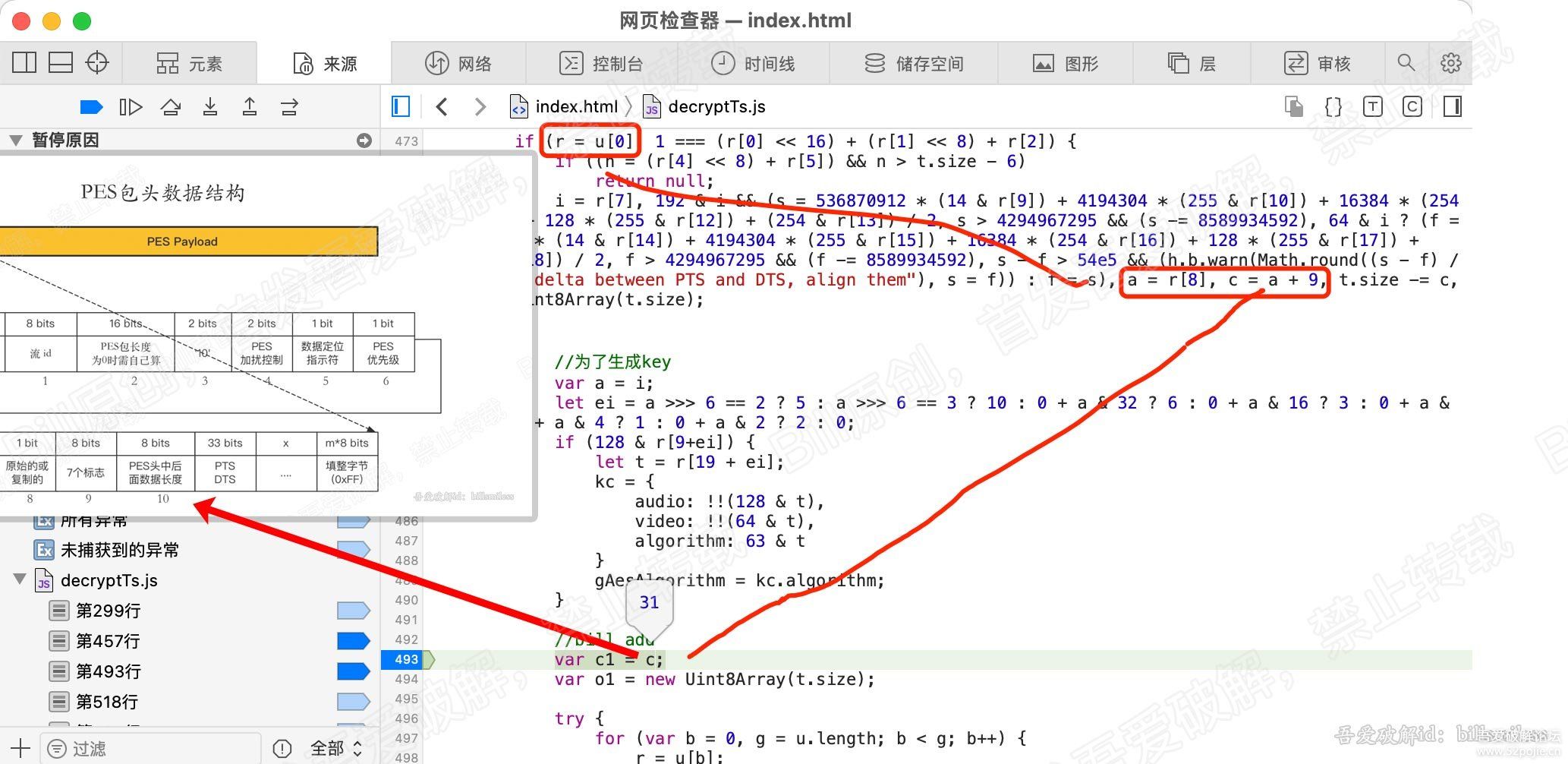
直接断点到493行,在这里我们分析下 c 的值,这个比较重要。
在476行, c = a + 9, a = r[8] , r = u[0], u其实就是我们的传进来的t.data
我们观察下u[0]的数据,发现开头的三个值是 0 0 1, 这3个值是 0x 00 00 01,表示PES包的开始。
所以u[0], 就是第一个ts包的负载,也就是包含pes包头的负载数据。
也就是说,r = u[0]的数据中是有pes头数据的。
结合我们上一章节的PES头数据格式,分析下a = r[8], 可以知道r[8]就是PES中占8bits的,PES头中后
面数据长度的字段。也就是说,r[8]的值就是PES头中,此字段后面的数据的长度。
那么 c = a + 9, 其实就是 PES头的总长度。此处c的值为31。
因为r[8]字段的值代表PES头后面剩余数据的长度,
加上本字节以及之前字节的长度,所以就是PES头的总长度了。
接下来继续分析:
将断点设在518行,继续执行,程序停留在518行。
查看下o的值、长度,以及t.data的第一个的值,对比下。看图:
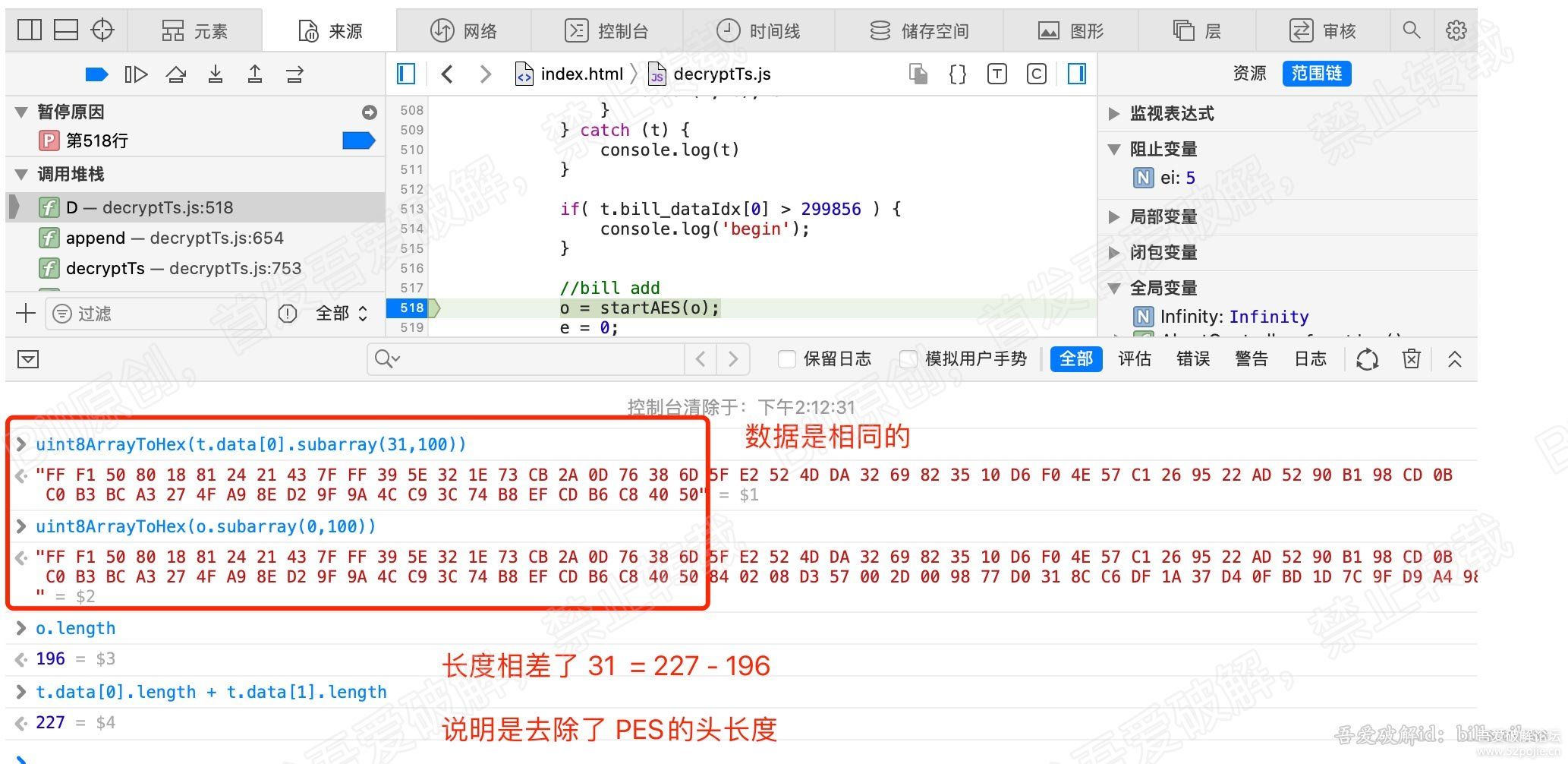
可以看到o的值比t.data的总长度少了 31,就是c的值。
再看o的值与t.data[0]的数据从第31个索引开始,是不是完全相同了。
说明上面497行的for循环做的事就是:将PES的数据合并到一起,并去除PES头的数据。o便是结果。
for (var b = 0, g = u.length; b < g; b++) {
r = u[b];
[/b] var v = r.byteLength;
if (c) {
if (c > v) {
c -= v;
continue
}
r = r.subarray(c), v -= c, c = 0
}
o.set(r, e), e += v
}再看518行:o = startAES(o);
此代码就是将 去除PES头的数据进行解密。得到解密后的数据。
本函数将解密后的PES数据返回。进行下一步处理。
由此我们知道,此ts的加密方式是对每个pes的负载数据(去除pes头)进行加密的。
至此,ts的加密逻辑分析完成。
总结下:
1、程序首先加载ts数据
2、每188个字节的循环,解析ts包
3、根据包的数据类型(pid判断),去进行不同的解析。
4、先解析PAT、得到PMT、得到其他媒体数据音视频等
5、将存在于多个ts包中的pes包的数据以及总大小,保存至变量。
6、将取得的PES包的数据和大小,传递给pes解析函数
7、解析函数将所有pes数据组装到一起并去除PES头
8、将组装的后的 pes数据,传给AES解密函数进行解密
9、得到解密后的PES数据,返回给播放器
我们现在知道了ts的数据是如何解析的,数据是在哪里解密的,以什么形式加密的。
那么接下来就来分析下,我们如何对ts文件进行解密。
四、如何进行解密
聪明的你,估计已经想到了。既然我们在上一章节拿到了解密数据,那么把解密数据,替换掉加密数据,然后重新保存ts,不就ok了吗
我只能说,聪明!!!
先分析下思路:
我们已知道 加密数据存在于多个ts包中,将多个ts中的数据提取,然后整和,再去解密,得到解密的整和数据。
所以,我们就要将 解密后的数据 进行拆分 到多个ts中。
得到解密的数据: 多个ts包 –> 得到待解密的pes –> 得到解密的数据
将解密数据还原: 解密的数据 –> 拆分到解密数据 –> 复原到多个ts包中
如何拆分解密的数据?
根据解密时,传递进来的整和的pes数据的size来进行拆分。
如何复原到ts包中?
记录解密时,获取pes数据时,pes数据所在的索引。
根据索引将相应的数据替换ts中的数据。
下面来具体操作:
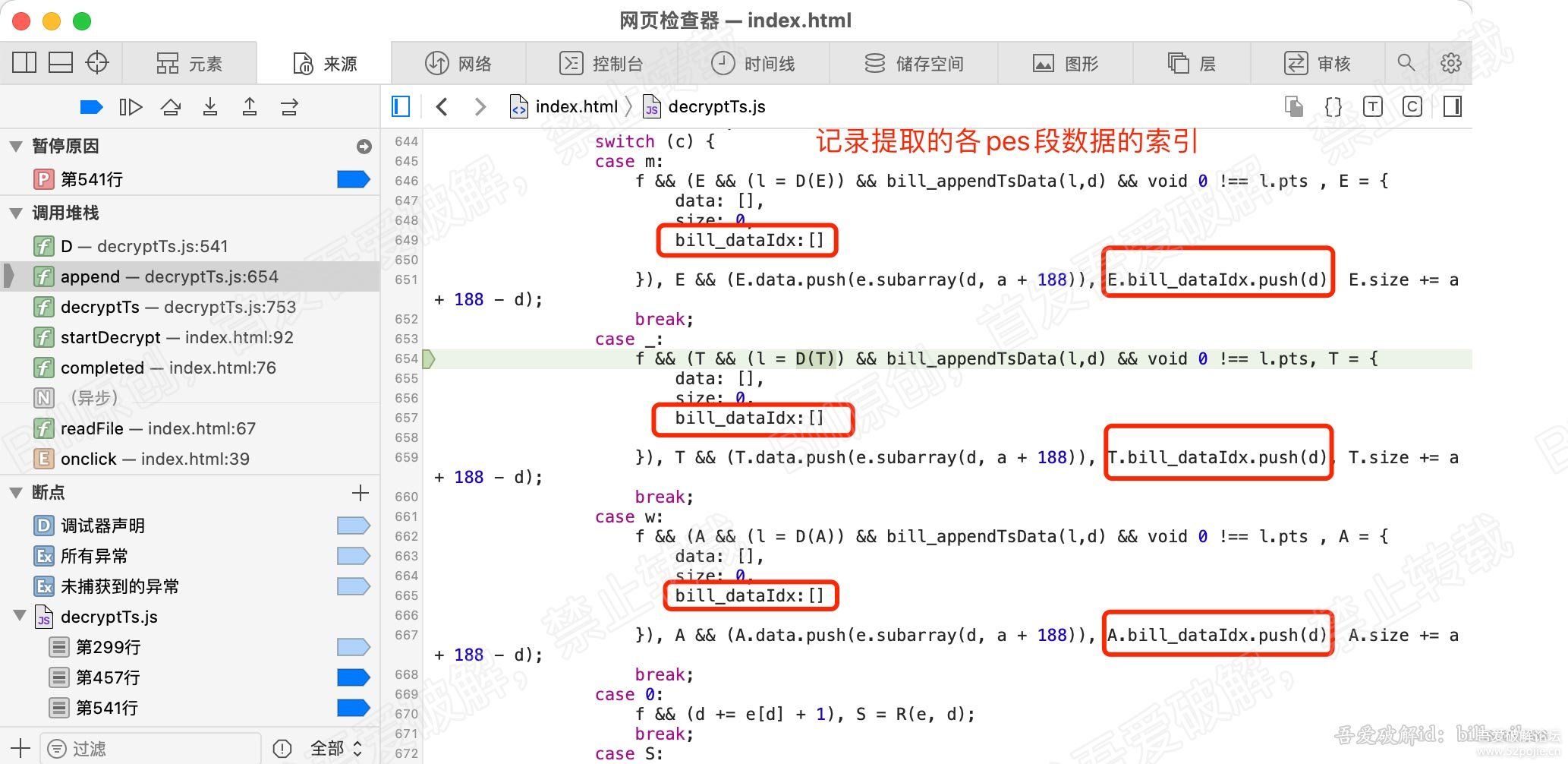
1、首先在ts中提取pes数据时,记录下提取数据的索引。
因为此时记录的索引是包含PES的头的长度。实际的解密数据是不包含PES头的。
所以我们要把索引传递到pes解析函数中,因为只有在pes解析函数中,才能拿到pes头的长度。
拿到pes头的长度后,把有pes包头的 的数据的索引值去掉pes头的长度。
上代码,在所有提取pes数据的地方,添加索引数组,并记录提取pes数据的索引。看图:
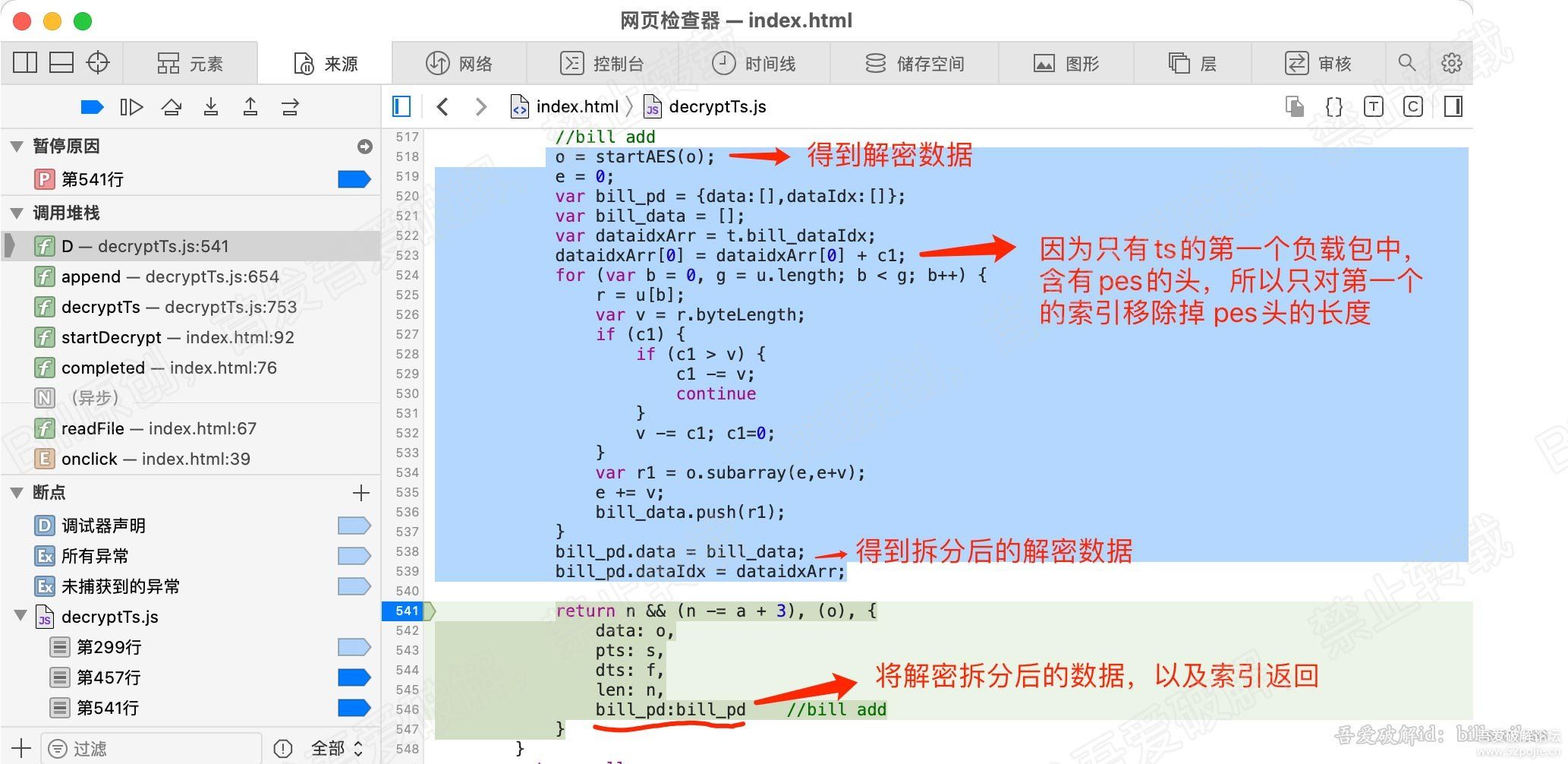
2、接下来在解析pes的函数中,对得到的pes解密数据进行拆分。
其实拆分与组合是类似,方向相反。根据传进来的pes数据的大小,以及ts包的数量来拆分。
拿到解密的数据,拆分后,将数据保存,同时将第一个含有pes头的索引加上pes头的长度。
将索引和拆分的数据,一同随其他数据返回。
每解析一个pes,我们就替换一个原始的未解密的pes数据。看图:
3、在解析ts的append函数中,收到拆分了解密的PES数据以及索引后,开始替换ts的原加密数据。
先看下解密的数据替换的函数:
function bill_appendTsData(nd, idx) {
//idx 没有用到,可忽略
var i = 0,j = 0;
let dataArr = nd.bill_pd.data;
let idxArr = nd.bill_pd.dataIdx;
let len = dataArr.length;
if( len != idxArr.length ) {
console.log('数据索引与数据数量不同');
return;
}
for( i = 0; i < len; i++ ) {
let darr = dataArr[i];
let didx = idxArr[i];
for ( j = 0; j < darr.length; j++) {
bill_d[didx+j] = darr[j];
}
}
}其实很简单,根据拿到的解密的数据和数据在ts文件的索引,替换相应的数据。
这里打了个断点,看下接收到的拆分后的解密数据以及索引。
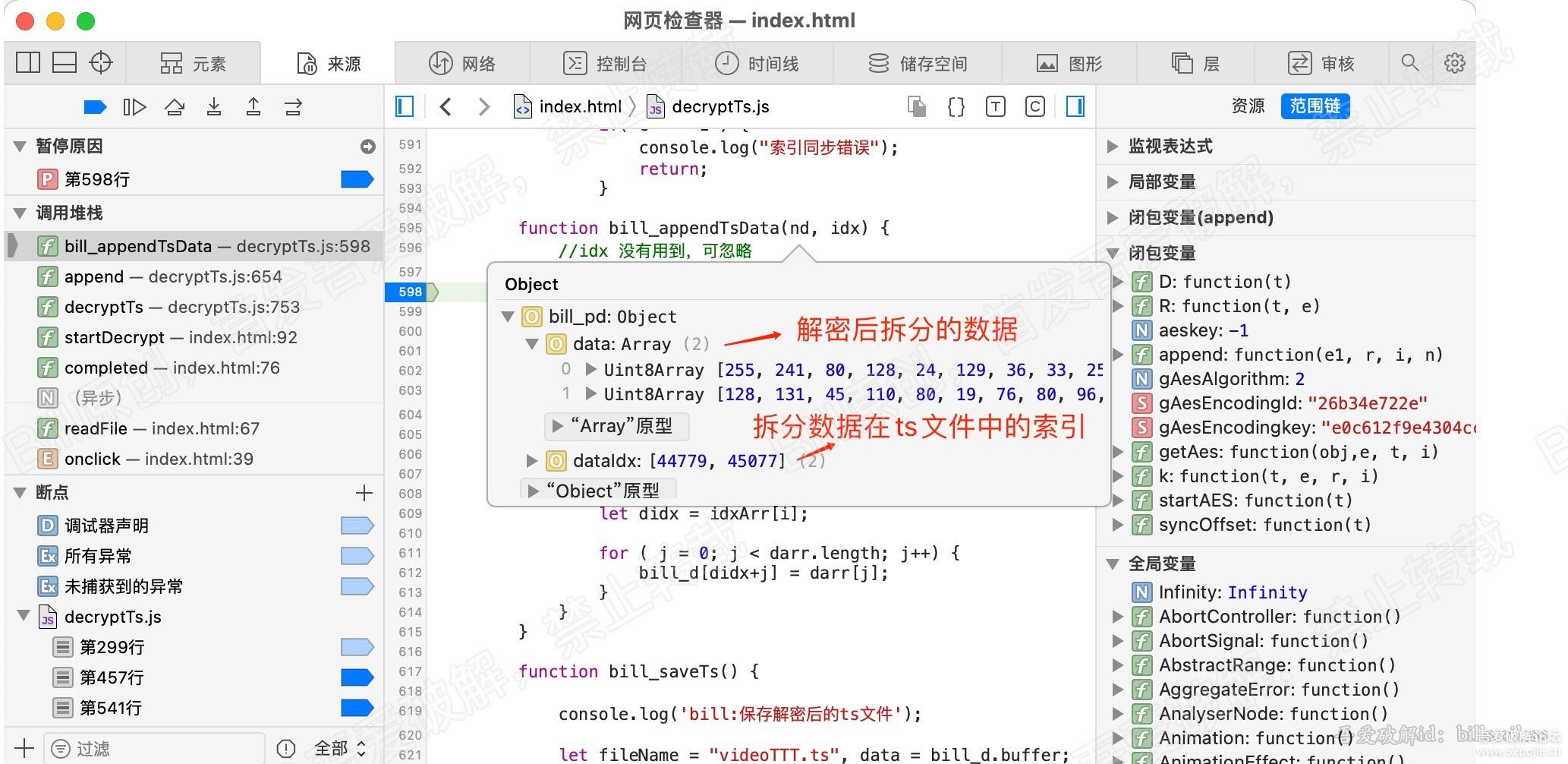
这是替换函数,看下在哪里调用替换函数。在收到解密的pes数据后,紧接着就调用。
此外,当for循环结束后,还需要对3个类型的ts包的数据,进行解密一次。
为什么这么做?大家思考啊
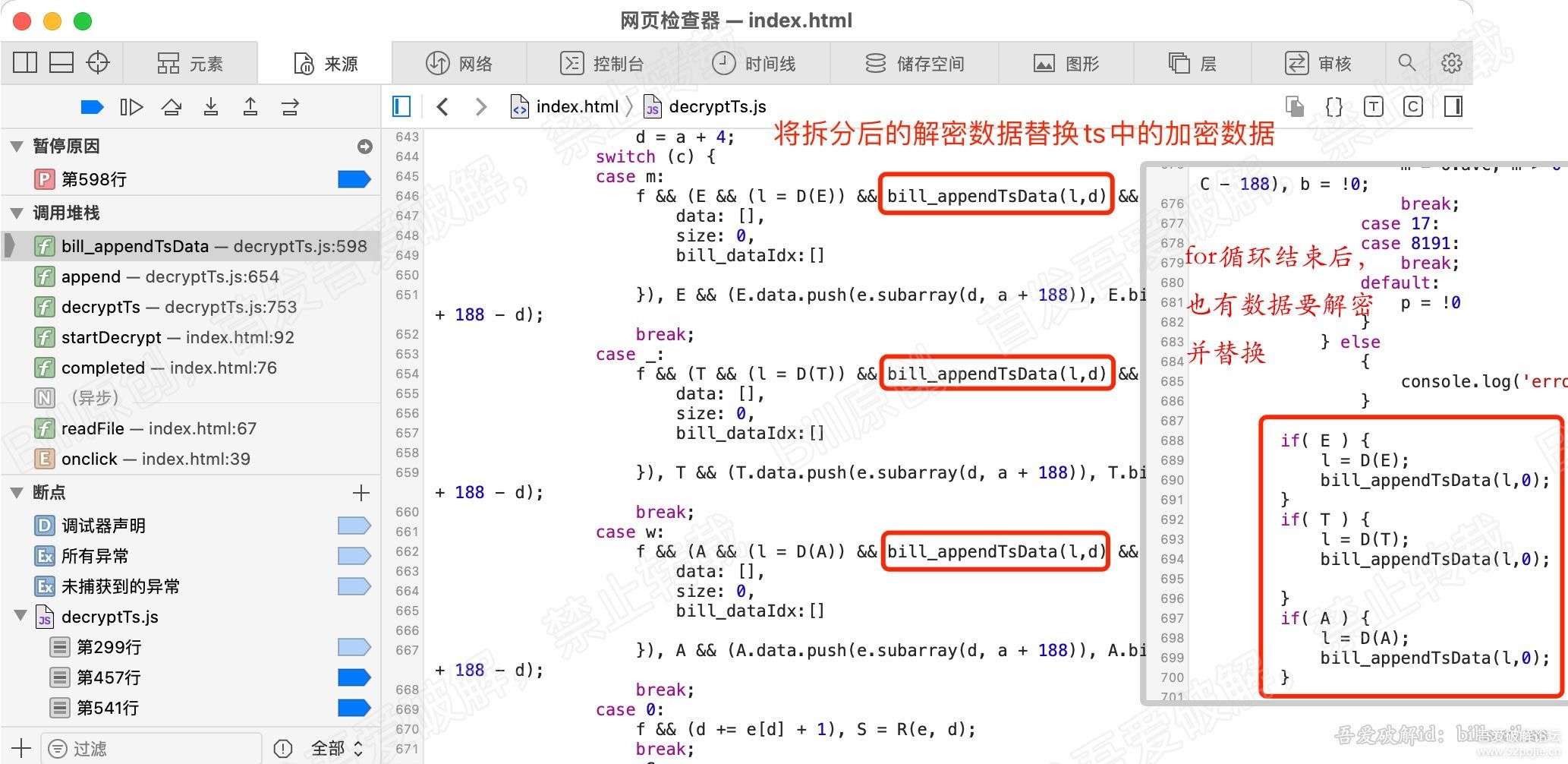
至此,PES解密分析就完成了。
五、总结以及demo
demo源码和示例视频,我上传到网盘了,下图为demo示例

总结
1、在某代码中,js函数如果不写返回值,竟然不会返回。之前代码正常。
2、关于ts包和pes包的关系,理解了很久,最后结合代码和文章,才弄清楚最终逻辑,有些文章内容是错的,会带跑偏。
3、对于代码中ts头和pes头的分析,也思考了很久,有时候半天想不明白。
4、对于ts数据格式,什么PAT等等各种表,懵逼的狠。也是结合代码,总算梳理明白了。
5、文章写了3天,梳理ts的知识,梳理代码,准备素材,再整理成文,期望对大家有所帮助。
6、因本人水平有限,文中若有错误之处,还望各位批评指正,共同进步。





![图片[1] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-1.png)
![图片[2] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-2-1.png)
![图片[3] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-3-1024x128-1.png)
![图片[4] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-4-1.png)
![图片[5] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-6-1.png)
![图片[6] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-7.png)
![图片[7] - 小说站94采集器安装教程-杰奇CMS采集 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-8-1.png)





![图片[1] - 小说站94采集器之系统设置(图文+视频)教程 - 长江技术博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-2.png)
![图片[2] - 小说站94采集器之系统设置(图文+视频)教程 - 长江技术博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-3.png)
![图片[3] - 小说站94采集器之系统设置(图文+视频)教程 - 长江技术博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-5.png)
![图片[4] - 小说站94采集器之系统设置(图文+视频)教程 - 长江技术博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-6.png)
![图片[5] - 小说站94采集器之系统设置(图文+视频)教程 - 长江技术博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-11.png)

![图片[1] - 小说站94采集器之采集规则编写(图文+视频)教程 - 长江技术博客](https://www.wucuoym.com/wp-content/uploads/2023/07/1076-1.png)
![图片[2] - 小说站94采集器之采集规则编写(图文+视频)教程 - 长江技术博客](https://www.wucuoym.com/wp-content/uploads/2023/07/1076-2.png)
![图片[3] - 小说站94采集器之采集规则编写(图文+视频)教程 - 长江技术博客](https://www.wucuoym.com/wp-content/uploads/2023/07/1076-3.png)

![图片[1] - 网站安全设置-苹果CMS安全设置教程 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/fd31dc5ce9dd.jpg)
![图片[2] - 网站安全设置-苹果CMS安全设置教程 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-26.png)
![图片[3] - 网站安全设置-苹果CMS安全设置教程 - 长江博客](https://www.wucuoym.com/wp-content/uploads/2023/07/image-24.png)